MIRI 2024 Communications Strategy
post by Gretta Duleba (gretta-duleba) · 2024-05-29T19:33:39.169Z · LW · GW · 216 commentsContents
The Objective: Shut it Down[1] Theory of Change Audience Message and Tone Channels Artifacts What We’re Not Doing Execution How to Help None 216 comments
As we explained in our MIRI 2024 Mission and Strategy update [LW · GW], MIRI has pivoted to prioritize policy, communications, and technical governance research over technical alignment research. This follow-up post goes into detail about our communications strategy.
The Objective: Shut it Down[1]
Our objective is to convince major powers to shut down the development of frontier AI systems worldwide before it is too late. We believe that nothing less than this will prevent future misaligned smarter-than-human AI systems from destroying humanity. Persuading governments worldwide to take sufficiently drastic action will not be easy, but we believe this is the most viable path.
Policymakers deal mostly in compromise: they form coalitions by giving a little here to gain a little somewhere else. We are concerned that most legislation intended to keep humanity alive will go through the usual political processes and be ground down into ineffective compromises.
The only way we think we will get strong enough legislation is if policymakers actually get it, if they actually come to understand that building misaligned smarter-than-human systems will kill everyone, including their children. They will pass strong enough laws and enforce them if and only if they come to understand this central truth.
Meanwhile, the clock is ticking. AI labs continue to invest in developing and training more powerful systems. We do not seem to be close to getting the sweeping legislation we need. So while we lay the groundwork for helping humanity to wake up, we also have a less dramatic request. We ask that governments and AI labs install the “off-switch”[2] so that if, on some future day, they decide to shut it all down, they will be able to do so.
We want humanity to wake up and take AI x-risk seriously. We do not want to shift the Overton window, we want to shatter it.
Theory of Change
Now I’ll get into the details of how we’ll go about achieving our objective, and why we believe this is the way to do it. The facets I’ll consider are:
- Audience: To whom are we speaking?
- Message and tone: How do we sound when we speak?
- Channels: How do we reach our audience?
- Artifacts: What, concretely, are we planning to produce?
Audience
The main audience we want to reach is policymakers – the people in a position to enact the sweeping regulation and policy we want – and their staff.
However, narrowly targeting policymakers is expensive and probably insufficient. Some of them lack the background to be able to verify or even reason deeply about our claims. We must also reach at least some of the people policymakers turn to for advice. We are hopeful about reaching a subset of policy advisors who have the skill of thinking clearly and carefully about risk, particularly those with experience in national security. While we would love to reach the broader class of bureaucratically-legible “AI experts,” we don’t expect to convince a supermajority of that class, nor do we think this is a requirement.
We also need to reach the general public. Policymakers, especially elected ones, want to please their constituents, and the more the general public calls for regulation, the more likely that regulation becomes. Even if the specific measures we want are not universally popular, we think it helps a lot to have them in play, in the Overton window.
Most of the content we produce for these three audiences will be fairly basic, 101-level material. However, we don’t want to abandon our efforts to reach deeply technical people as well. They are our biggest advocates, most deeply persuaded, most likely to convince others, and least likely to be swayed by charismatic campaigns in the opposite direction. And more importantly, discussions with very technical audiences are important for putting ourselves on trial. We want to be held to a high standard and only technical audiences can do that.
Message and Tone
Since I joined MIRI as the Communications Manager a year ago, several people have told me we should be more diplomatic and less bold. The way you accomplish political goals, they said, is to play the game. You can’t be too out there, you have to stay well within the Overton window, you have to be pragmatic. You need to hoard status and credibility points, and you shouldn’t spend any on being weird.
While I believe those people were kind and had good intentions, we’re not following their advice. Many other organizations are taking that approach. We’re doing something different. We are simply telling the truth as we know it.
We do this for three reasons.
- Many other organizations are attempting the coalition-building, horse-trading, pragmatic approach. In private, many of the people who work at those organizations agree with us, but in public, they say the watered-down version of the message. We think there is a void at the candid end of the communication spectrum that we are well positioned to fill.
- We think audiences are numb to politics as usual. They know when they’re being manipulated. We have opted out of the political theater, the kayfabe, with all its posing and posturing. We are direct and blunt and honest, and we come across as exactly what we are.
- Probably most importantly, we believe that “pragmatic” political speech won't get the job done. The political measures we’re asking for are a big deal; nothing but the full unvarnished message will motivate the action that is required.
These people who offer me advice often assume that we are rubes, country bumpkins coming to the big city for the first time, simply unaware of how the game is played, needing basic media training and tutoring. They may be surprised to learn that we arrived at our message and tone thoughtfully, having considered all the options. We communicate the way we do intentionally because we think it has the best chance of real success. We understand that we may be discounted or uninvited in the short term, but meanwhile our reputation as straight shooters with a clear and uncomplicated agenda remains intact. We also acknowledge that we are relatively new to the world of communications and policy, we’re not perfect, and it is very likely that we are making some mistakes or miscalculations; we’ll continue to pay attention and update our strategy as we learn.
Channels
So far, we’ve experimented with op-eds, podcasts, and interviews with newspapers, magazines, and radio journalists. It’s hard to measure the effectiveness of these various channels, so we’re taking a wide-spectrum approach. We’re continuing to pursue all of these, and we’d like to expand into books, videos, and possibly film.
We also think in terms of two kinds of content: stable, durable, proactive content – called “rock” content – and live, reactive content that is responsive to current events – called “wave” content. Rock content includes our website, blog articles, books, and any artifact we make that we expect to remain useful for multiple years. Wave content, by contrast, is ephemeral, it follows the 24-hour news cycle, and lives mostly in social media and news.
We envision a cycle in which someone unfamiliar with AI x-risk might hear about us for the first time on a talk show or on social media – wave content – become interested in our message, and look us up to learn more. They might find our website or a book we wrote – rock content – and become more informed and concerned. Then they might choose to follow us on social media or subscribe to our newsletter – wave content again – so they regularly see reminders of our message in their feeds, and so on.
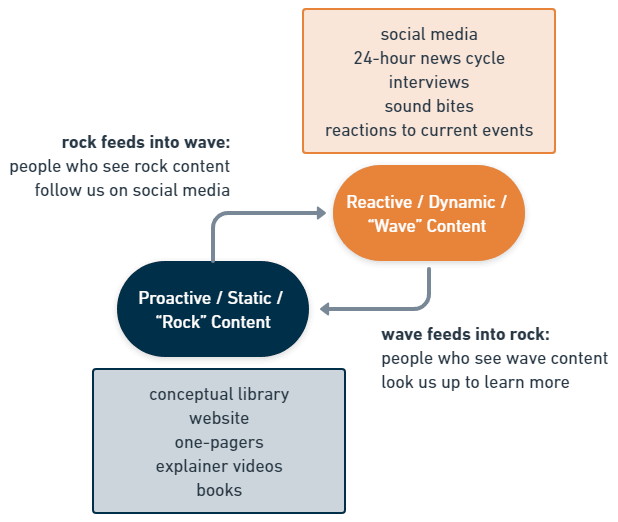
These are pretty standard communications tactics in the modern era. However, mapping out this cycle allows us to identify where we may be losing people, where we need to get stronger, where we need to build out more infrastructure or capacity.
Artifacts
What we find, when we map out that cycle, is that we have a lot of work to do almost everywhere, but that we should probably start with our rock content. That’s the foundation, the bedrock, the place where investment pays off the most over time.
And as such, we are currently exploring several communications projects in this area, including:
- a new MIRI website, aimed primarily at making the basic case for AI x-risk to newcomers to the topic, while also establishing MIRI’s credibility
- a short, powerful book for general audiences
- a detailed online reference exploring the nuance and complexity that we will need to refrain from including in the popular science book
We have a lot more ideas than that, but we’re still deciding which ones we’ll invest in.
What We’re Not Doing
Focus helps with execution; it is also important to say what the comms team is not going to invest in.
We are not investing in grass-roots advocacy, protests, demonstrations, and so on. We don’t think it plays to our strengths, and we are encouraged that others are making progress in this area. Some of us as individuals do participate in protests.
We are not currently focused on building demos of frightening AI system capabilities. Again, this work does not play to our current strengths, and we see others working on this important area. We think the capabilities that concern us the most can’t really be shown in a demo; by the time they can, it will be too late. However, we appreciate and support the efforts of others to demonstrate intermediate or precursor capabilities.
We are not particularly investing in increasing Eliezer’s personal influence, fame, or reach; quite the opposite. We already find ourselves bottlenecked on his time, energy, and endurance. His profile will probably continue to grow as the public pays more and more attention to AI; a rising tide lifts all boats. However, we would like to diversify the public face of MIRI and potentially invest heavily in a spokesperson who is not Eliezer, if we can identify the right candidate.
Execution
The main thing holding us back from realizing this vision is staffing. The communications team is small, and there simply aren’t enough hours in the week to make progress on everything. As such, we’ve been hiring, and we intend to hire more.
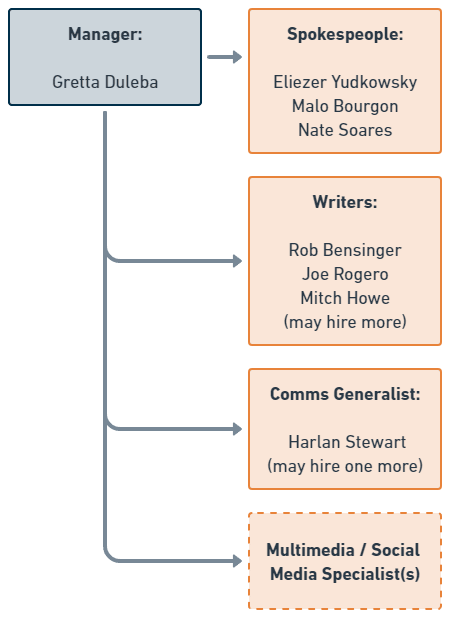
We hope to hire more writers and we may promote someone into a Managing Editor position. We are exploring the idea of hiring or partnering with additional spokespeople, as well as hiring an additional generalist to run projects and someone to specialize in social media and multimedia.
Hiring for these roles is hard because we are looking for people who have top-tier communications skills, know how to restrict themselves to valid arguments, and are aligned with MIRI’s perspective. It’s much easier to find candidates with one or two of those qualities than to find people in the intersection. For these first few key hires we felt it was important to check all the boxes. We hope that once the team is bigger, it may be possible to hire people who write compelling, valid prose and train them on MIRI’s perspective. Our current sense is that it’s easier to explain AI x-risk to a competent, valid writer than it is to explain great writing to someone who already shares our perspective.
How to Help
The best way you can help is to normalize the subject of AI x-risk. We think many people who have been “in the know” about AI x-risk have largely kept silent about it over the years, or only talked to other insiders. If this describes you, we’re asking you to reconsider this policy, and try again (or for the first time) to talk to your friends and family about this topic. Find out what their questions are, where they get stuck, and try to help them through those stuck places.
As MIRI produces more 101-level content on this topic, share that content with your network. Tell us how it performs. Tell us if it actually helps, or where it falls short. Let us know what you wish we would produce next. (We're especially interested in stories of what actually happened, not just considerations of what might happen, when people encounter our content.)
Going beyond networking, please vote with AI x-risk considerations in mind.
If you are one of those people who has great communication skills and also really understands x-risk, come and work for us! Or share our job listings with people you know who might fit.
Subscribe to our newsletter. There’s a subscription form on our Get Involved page.
And finally, later this year we’ll be fundraising for the first time in five years, and we always appreciate your donations.
Thank you for reading and we look forward to your feedback.
- ^
We remain committed to the idea that failing to build smarter-than-human systems someday would be tragic and would squander a great deal of potential. We want humanity to build those systems, but only once we know how to do so safely.
- ^
By “off-switch” we mean that we would like labs and governments to plan ahead, to implement international AI compute governance frameworks and controls sufficient for halting the development of any dangerous AI development activity, and streamlined functional processes for doing so.
216 comments
Comments sorted by top scores.
comment by Matthew Barnett (matthew-barnett) · 2024-05-30T23:30:10.598Z · LW(p) · GW(p)
I appreciate the straightforward and honest nature of this communication strategy, in the sense of "telling it like it is" and not hiding behind obscure or vague language. In that same spirit, I'll provide my brief, yet similarly straightforward reaction to this announcement:
- I think MIRI is incorrect in their assessment of the likelihood of human extinction from AI. As per their messaging, several people at MIRI seem to believe that doom is >80% likely in the 21st century (conditional on no global pause) whereas I think it's more like <20%.
- MIRI's arguments for doom are often difficult to pin down, given the informal nature of their arguments, and in part due to their heavy reliance on analogies, metaphors, and vague supporting claims instead of concrete empirically verifiable models. Consequently, I find it challenging to respond to MIRI's arguments precisely. The fact that they want to essentially shut down the field of AI based on these largely informal arguments seems premature to me.
- MIRI researchers rarely provide any novel predictions about what will happen before AI doom, making their theories of doom appear unfalsifiable. This frustrates me. Given a low prior probability of doom as apparent from the empirical track record of technological progress, I think we should generally be skeptical of purely theoretical arguments for doom, especially if they are vague and make no novel, verifiable predictions prior to doom.
- Separately from the previous two points, MIRI's current most prominent arguments for doom [LW · GW] seem very weak to me. Their broad model of doom appears to be something like the following (although they would almost certainly object to the minutia of how I have written it here):
(1) At some point in the future, a powerful AGI will be created. This AGI will be qualitatively distinct from previous, more narrow AIs. Unlike concepts such as "the economy", "GPT-4", or "Microsoft", this AGI is not a mere collection of entities or tools integrated into broader society that can automate labor, share knowledge, and collaborate on a wide scale. This AGI is instead conceived of as a unified and coherent decision agent, with its own long-term values that it acquired during training. As a result, it can do things like lie about all of its fundamental values and conjure up plans of world domination, by itself, without any risk of this information being exposed to the wider world.
(2) This AGI, via some process such as recursive self-improvement, will rapidly "foom" until it becomes essentially an immortal god, at which point it will be able to do almost anything physically attainable, including taking over the world at almost no cost or risk to itself. While recursive self-improvement is the easiest mechanism to imagine here, it is not the only way this could happen.
(3) The long-term values of this AGI will bear almost no relation to the values that we tried to instill through explicit training, because of difficulties in inner alignment (i.e., a specific version of the general phenomenon of models failing to generalize correctly from training data). This implies that the AGI will care almost literally 0% about the welfare of humans (despite potentially being initially trained from the ground up on human data, and carefully inspected and tested by humans for signs of misalignment, in diverse situations and environments). Instead, this AGI will pursue a completely meaningless goal until the heat death of the universe.
(4) Therefore, the AGI will kill literally everyone after fooming and taking over the world. - It is difficult to explain in a brief comment why I think the argument just given is very weak. Instead of going into the various subclaims here in detail, for now I want to simply say, "If your model of reality has the power to make these sweeping claims with high confidence, then you should almost certainly be able to use your model of reality to make novel predictions about the state of the world prior to AI doom that would help others determine if your model is correct."
The fact that MIRI has yet to produce (to my knowledge) any major empirically validated predictions or important practical insights into the nature of AI, or AI progress, in the last 20 years, undermines the idea that they have the type of special insight into AI that would allow them to express high confidence in a doom model like the one outlined in (4). - Eliezer's response to claims about unfalsifiability, namely that "predicting endpoints is easier than predicting intermediate points", seems like a cop-out to me, since this would seem to reverse the usual pattern in forecasting and prediction, without good reason.
- Since I think AI will most likely be a very good thing for currently existing people, I am much more hesitant to "shut everything down" compared to MIRI. I perceive MIRI researchers as broadly well-intentioned, thoughtful, yet ultimately fundamentally wrong in their worldview on the central questions that they research, and therefore likely to do harm to the world. This admittedly makes me sad to think about.
↑ comment by quetzal_rainbow · 2024-05-31T19:32:05.717Z · LW(p) · GW(p)
Eliezer's response to claims about unfalsifiability, namely that "predicting endpoints is easier than predicting intermediate points", seems like a cop-out to me, since this would seem to reverse the usual pattern in forecasting and prediction, without good reason
It's pretty standard? Like, we can make reasonable prediction of climate in 2100, even if we can't predict weather two month ahead.
Replies from: Benjy_Forstadt, 1a3orn, matthew-barnett, logan-zoellner, Prometheus↑ comment by Benjy_Forstadt · 2024-06-01T15:27:34.381Z · LW(p) · GW(p)
To be blunt, it's not just that Eliezer lacks a positive track record in predicting the nature of AI progress, which might be forgivable if we thought he had really good intuitions about this domain. Empiricism isn't everything, theoretical arguments are important too and shouldn't be dismissed. But-
Eliezer thought AGI would be developed from a recursively self-improving seed AI coded up by a small group, "brain in a box in a basement" style. He dismissed and mocked connectionist approaches to building AI. His writings repeatedly downplayed the importance of compute, and he has straw-manned writers like Moravec who did a better job at predicting when AGI would be developed than he did.
Old MIRI intuition pumps about why alignment should be difficult like the "Outcome Pump" and "Sorcerer's apprentice" are now forgotten, it was a surprise that it would be easy to create helpful genies like LLMs who basically just do what we want. Remaining arguments for the difficulty of alignment are esoteric considerations about inductive biases, counting arguments, etc. So yes, let's actually look at these arguments and not just dismiss them, but let's not pretend that MIRI has a good track record.
↑ comment by dr_s · 2024-06-03T09:20:53.639Z · LW(p) · GW(p)
I think the core concerns remain, and more importantly, there are other rather doom-y scenarios possible involving AI systems more similar to the ones we have that opened up and aren't the straight up singleton ASI foom. The problem here is IMO not "this specific doom scenario will become a thing" but "we don't have anything resembling a GOOD vision of the future with this tech that we are nevertheless developing at breakneck pace". Yet the amount of dystopian or apocalyptic possible scenarios is enormous. Part of this is "what if we lose control of the AIs" (singleton or multipolar), part of it is "what if we fail to structure our society around having AIs" (loss of control, mass wireheading, and a lot of other scenarios I'm not sure how to name). The only positive vision the "optimists" on this have to offer is "don't worry, it'll be fine, this clearly revolutionary and never seen before technology that puts in question our very role in the world will play out the same way every invention ever did". And that's not terribly convincing.
↑ comment by quetzal_rainbow · 2024-06-01T16:53:39.368Z · LW(p) · GW(p)
I'm not saying anything on object-level about MIRI models, my point is that "outcomes are more predictable than trajectories" is pretty standard epistemically non-suspicious statement about wide range of phenomena. Moreover, in particular circumstances (and many others) you can reduce it to object-level claim, like "do observarions on current AIs generalize to future AI?"
Replies from: Benjy_Forstadt↑ comment by Benjy_Forstadt · 2024-06-01T21:53:30.894Z · LW(p) · GW(p)
How does the question of whether AI outcomes are more predictable than AI trajectories reduce to the (vague) question of whether observations on current AIs generalize to future AIs?
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-06-02T10:43:54.604Z · LW(p) · GW(p)
ChatGPT falsifies prediction about future superintelligent recursive self-improving AI only if ChatGPT is generalizable predictor of design of future superintelligent AIs.
Replies from: Benjy_Forstadt↑ comment by Benjy_Forstadt · 2024-06-02T14:31:18.689Z · LW(p) · GW(p)
There will be future superintelligent AIs that improve themselves. But they will be neural networks, they will at the very least start out as a compute-intensive project, in the infant stages of their self-improvement cycles they will understand and be motivated by human concepts rather than being dumb specialized systems that are only good for bootstrapping themselves to superintelligence.
Replies from: Benjy_Forstadt↑ comment by Benjy_Forstadt · 2024-06-06T02:30:30.902Z · LW(p) · GW(p)
Edit: Retracted because some of my exegesis of the historical seed AI concept may not be accurate
↑ comment by 1a3orn · 2024-05-31T19:51:03.203Z · LW(p) · GW(p)
True knowledge about later times doesn't let you generally make arbitrary predictions about intermediate times, given valid knowledge of later times. But true knowledge does usually imply that you can make some theory-specific predictions about intermediate times, given later times.
Thus, vis-a-vis your examples: Predictions about the climate in 2100 don't involve predicting tomorrow's weather. But they do almost always involve predictions about the climate in 2040 and 2070, and they'd be really sus if they didn't.
Similarly:
- If an astronomer thought that an asteroid was going to hit the earth, the astronomer generally could predict points it will be observed at in the future before hitting the earth. This is true even if they couldn't, for instance, predict the color of the asteroid.
- People who predicted that C19 would infect millions by T + 5 months also had predictions about how many people would be infected at T + 2. This is true even if they couldn't predict how hard it would be to make a vaccine.
- (Extending analogy to scale rather than time) The ability to predict that nuclear war would kill billions involves a pretty good explanation for how a single nuke would kill millions.
So I think that -- entirely apart from specific claims about whether MIRI does this -- it's pretty reasonable to expect them to be able to make some theory-specific predictions about the before-end-times, although it's unreasonable to expect them to make arbitrary theory-specific predictions.
Replies from: aysja, DPiepgrass↑ comment by aysja · 2024-05-31T20:59:53.573Z · LW(p) · GW(p)
I agree this is usually the case, but I think it’s not always true, and I don’t think it’s necessarily true here. E.g., people as early as Da Vinci guessed that we’d be able to fly long before we had planes (or even any flying apparatus which worked). Because birds can fly, and so we should be able to as well (at least, this was Da Vinci and the Wright brothers' reasoning). That end point was not dependent on details (early flying designs had wings like a bird, a design which we did not keep :p), but was closer to a laws of physics claim (if birds can do it there isn’t anything fundamentally holding us back from doing it either).
Superintelligence holds a similar place in my mind: intelligence is physically possible, because we exhibit it, and it seems quite arbitrary to assume that we’ve maxed it out. But also, intelligence is obviously powerful, and reality is obviously more manipulable than we currently have the means to manipulate it. E.g., we know that we should be capable of developing advanced nanotech, since cells can, and that space travel/terraforming/etc. is possible.
These two things together—“we can likely create something much smarter than ourselves” and “reality can be radically transformed”—is enough to make me feel nervous. At some point I expect most of the universe to be transformed by agents; whether this is us, or aligned AIs, or misaligned AIs or what, I don’t know. But looking ahead and noticing that I don’t know how to select the “aligned AI” option from the set “things which will likely be able to radically transform matter” seems enough cause, in my mind, for exercising caution.
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-05-31T21:55:11.572Z · LW(p) · GW(p)
There's a pretty big difference between statements like "superintelligence is physically possible", "superintelligence could be dangerous" and statements like "doom is >80% likely in the 21st century unless we globally pause". I agree with (and am not objecting to) the former claims, but I don't agree with the latter claim.
I also agree that it's sometimes true that endpoints are easier to predict than intermediate points. I haven't seen Eliezer give a reasonable defense of this thesis as it applies to his doom model. If all he means here is that superintelligence is possible, it will one day be developed, and we should be cautious when developing it, then I don't disagree. But I think he's saying a lot more than that.
↑ comment by DPiepgrass · 2024-07-15T22:58:06.710Z · LW(p) · GW(p)
Your general point is true, but it's not necessarily true that a correct model can (1) predict the timing of AGI or (2) that the predictable precursors to disaster occur before the practical c-risk (catastrophic-risk) point of no return. While I'm not as pessimistic as Eliezer, my mental model has these two limitations. My model does predict that, prior to disaster, a fairly safe, non-ASI AGI or pseudo-AGI (e.g. GPT6, a chatbot that can do a lot of office jobs and menial jobs pretty well) is likely to be invented before the really deadly one (if any[1]). But if I predicted right, it probably won't make people take my c-risk concerns more seriously?
- ^
technically I think AGI inevitably ends up deadly, but it could be deadly "in a good way"
↑ comment by Matthew Barnett (matthew-barnett) · 2024-05-31T19:40:23.009Z · LW(p) · GW(p)
I think it's more similar to saying that the climate in 2040 is less predictable than the climate in 2100, or saying that the weather 3 days from now is less predictable than the weather 10 days from now, which are both not true. By contrast, the weather vs. climate distinction is more of a difference between predicting point estimates vs. predicting averages.
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-05-31T22:29:24.989Z · LW(p) · GW(p)
the climate in 2040 is less predictable than the climate in 2100
It's certainly not a simple question. Say, Gulf Stream is projected to collapse somewhere between now and 2095, with median date 2050. So, slightly abusing meaning of confidence intervals, we can say that in 2100 we won't have Gulf Stream with probability >95%, while in 2040 Gulf Stream will still be here with probability ~60%, which is literally less predictable.
Chemists would give an example of chemical reactions, where final thermodynamically stable states are easy to predict, while unstable intermediate states are very hard to even observe.
Very dumb example: if you are observing radioactive atom with half-life of one minute, you can't predict when atom is going to decay, but you can be very certain that it will decay after hour.
And why don't you accept classic MIRI example that even if it's impossible for human to predict moves of Stockfish 16, you can be certain that Stockfish will win?
Replies from: matthew-barnett, dr_s↑ comment by Matthew Barnett (matthew-barnett) · 2024-05-31T22:44:35.718Z · LW(p) · GW(p)
Chemists would give an example of chemical reactions, where final thermodynamically stable states are easy to predict, while unstable intermediate states are very hard to even observe.
I agree there are examples where predicting the end state is easier to predict than the intermediate states. Here, it's because we have strong empirical and theoretical reasons to think that chemicals will settle into some equilibrium after a reaction. With AGI, I have yet to see a compelling argument for why we should expect a specific easy-to-predict equilibrium state after it's developed, which somehow depends very little on how the technology is developed.
It's also important to note that, even if we know that there will be an equilibrium state after AGI, more evidence is generally needed to establish that the end equilibrium state will specifically be one in which all humans die.
And why don't you accept classic MIRI example that even if it's impossible for human to predict moves of Stockfish 16, you can be certain that Stockfish will win?
I don't accept this argument as a good reason to think doom is highly predictable partly because I think the argument is dramatically underspecified without shoehorning in assumptions about what AGI will look like to make the argument more comprehensible. I generally classify arguments like this under the category of "analogies that are hard to interpret because the assumptions are so unclear".
To help explain my frustration at the argument's ambiguity, I'll just give a small yet certainly non-exhaustive set of questions I have about this argument:
- Are we imagining that creating an AGI implies that we play a zero-sum game against it? Why?
- Why is it a simple human vs. AGI game anyway? Does that mean we're lumping together all the humans into a single agent, and all the AGIs into another agent, and then they play off against each other like a chess match? What is the justification for believing the battle will be binary like this?
- Are we assuming the AGI wants to win? Maybe it's not an agent at all. Or maybe it's an agent but not the type of agent that wants this particular type of outcome.
- What does "win" mean in the general case here? Does it mean the AGI merely gets more resources than us, or does it mean the AGI kills everyone? These seem like different yet legitimate ways that one can "win" in life, with dramatically different implications for the losing parties.
There's a lot more I can say here, but the basic point I want to make is that once you start fleshing this argument out, and giving it details, I think it starts to look a lot weaker than the general heuristic that Stockfish 16 will reliably beat humans in chess, even if we can't predict its exact moves.
Replies from: quetzal_rainbow↑ comment by dr_s · 2024-06-03T09:22:31.675Z · LW(p) · GW(p)
I don't think the Gulf Stream can collapse as long as the Earth spins, I guess you mean the AMOC?
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-06-03T09:48:18.210Z · LW(p) · GW(p)
Yep, AMOC is what I mean
↑ comment by Logan Zoellner (logan-zoellner) · 2024-06-05T13:23:40.245Z · LW(p) · GW(p)
>Like, we can make reasonable prediction of climate in 2100, even if we can't predict weather two month ahead.
This is a strange claim to make in a thread about AGI destroying the world. Obviously if AGI destroys the world we can not predict the weather in 2100.
Predicting the weather in 2100 requires you to make a number of detailed claims about the years between now and 2100 (for example, the carbon-emissions per year), and it is precisely the lack of these claims that @Matthew Barnett [LW · GW] is talking about.
↑ comment by Prometheus · 2024-06-05T18:14:33.707Z · LW(p) · GW(p)
I strongly doubt we can predict the climate in 2100. Actual prediction would be a model that also incorporates the possibility of nuclear fusion, geoengineering, AGIs altering the atmosphere, etc.
↑ comment by TurnTrout · 2024-05-31T21:26:08.339Z · LW(p) · GW(p)
"If your model of reality has the power to make these sweeping claims with high confidence, then you should almost certainly be able to use your model of reality to make novel predictions about the state of the world prior to AI doom that would help others determine if your model is correct."
This is partially derivable from Bayes rule. In order for you to gain confidence in a theory, you need to make observations which are more likely in worlds where the theory is correct. Since MIRI seems to have grown even more confident in their models, they must've observed something which is more likely to be correct under their models. Therefore, to obey Conservation of Expected Evidence [LW · GW], the world could have come out a different way which would have decreased their confidence. So it was falsifiable this whole time. However, in my experience, MIRI-sympathetic folk deny this for some reason.
It's simply not possible, as a matter of Bayesian reasoning, to lawfully update (today) based on empirical evidence (like LLMs succeeding) in order to change your probability of a hypothesis that "doesn't make" any empirical predictions (today).
The fact that MIRI has yet to produce (to my knowledge) any major empirically validated predictions or important practical insights into the nature AI, or AI progress, in the last 20 years, undermines the idea that they have the type of special insight into AI that would allow them to express high confidence in a doom model like the one outlined in (4).
In summer 2022, Quintin Pope was explaining the results of the ROME paper to Eliezer. Eliezer impatiently interrupted him and said "so they found that facts were stored in the attention layers, so what?". Of course, this was exactly wrong --- Bau et al. found the circuits in mid-network MLPs. Yet, there was no visible moment of "oops" for Eliezer.
Replies from: gwern, adam-jermyn, TsviBT, Lukas_Gloor↑ comment by gwern · 2024-05-31T21:35:30.780Z · LW(p) · GW(p)
In summer 2022, Quintin Pope was explaining the results of the ROME paper to Eliezer. Eliezer impatiently interrupted him and said "so they found that facts were stored in the attention layers, so what?". Of course, this was exactly wrong --- Bau et al. found the circuits in mid-network MLPs. Yet, there was no visible moment of "oops" for Eliezer.
I think I am missing context here. Why is that distinction between facts localized in attention layers and in MLP layers so earth-shaking Eliezer should have been shocked and awed by a quick guess during conversation being wrong, and is so revealing an anecdote you feel that it is the capstone of your comment, crystallizing everything wrong about Eliezer into a story?
Replies from: TurnTrout↑ comment by TurnTrout · 2024-06-02T06:11:24.992Z · LW(p) · GW(p)
^ Aggressive strawman which ignores the main point of my comment. I didn't say "earth-shaking" or "crystallizing everything wrong about Eliezer" or that the situation merited "shock and awe." Additionally, the anecdote was unrelated to the other section of my comment, so I didn't "feel" it was a "capstone."
I would have hoped, with all of the attention on this exchange, that someone would reply "hey, TurnTrout didn't actually say that stuff." You know, local validity and all that. I'm really not going to miss this site.
Anyways, gwern, it's pretty simple. The community edifies this guy and promotes his writing as a way to get better at careful reasoning. However, my actual experience is that Eliezer goes around doing things like e.g. impatiently interrupting people and being instantly wrong about it (importantly, in the realm of AI, as was the original context). This makes me think that Eliezer isn't deploying careful reasoning to begin with.
Replies from: nikolas-kuhn, nikolas-kuhn, gwern↑ comment by Amalthea (nikolas-kuhn) · 2024-06-02T06:46:07.584Z · LW(p) · GW(p)
That said, It also appears to me that Eliezer is probably not the most careful reasoner, and appears indeed often (perhaps egregiously) overconfident. That doesn't mean one should begrudge people finding value in the sequences although it is certainly not ideal if people take them as mantras rather than useful pointers and explainers for basic things (I didn't read them, so might have an incorrect view here). There does appear to be some tendency to just link to some point made in the sequences as some airtight thing, although I haven't found it too pervasive recently.
↑ comment by Amalthea (nikolas-kuhn) · 2024-06-02T06:34:31.391Z · LW(p) · GW(p)
You're describing a situational character flaw which doesn't really have any bearing on being able to reason carefully overall.
Replies from: thomas-kwa↑ comment by Thomas Kwa (thomas-kwa) · 2024-06-02T07:15:20.046Z · LW(p) · GW(p)
Disagree. Epistemics is a group project and impatiently interrupting people can make both you and your interlocutor less likely to combine your information into correct conclusions. It is also evidence that you're incurious internally which makes you worse at reasoning, though I don't want to speculate on Eliezer's internal experience in particular.
Replies from: nikolas-kuhn↑ comment by Amalthea (nikolas-kuhn) · 2024-06-02T08:01:56.356Z · LW(p) · GW(p)
I agree with the first sentence. I agree with the second sentence with the caveat that it's not strong absolute evidence, but mostly applies to the given setting (which is exactly what I'm saying).
People aren't fixed entities and the quality of their contributions can vary over time and depend on context.
↑ comment by gwern · 2024-06-04T21:00:34.013Z · LW(p) · GW(p)
^ Aggressive strawman which ignores the main point of my comment. I didn't say "earth-shaking" or "crystallizing everything wrong about Eliezer" or that the situation merited "shock and awe."
I, uh, didn't say you "say" either of those: I was sarcastically describing your comment about an anecdote that scarcely even seemed to illustrate what it was supposed to, much less was so important as to be worth recounting years later as a high profile story (surely you can come up with something better than that after all this time?), and did not put my description in quotes meant to imply literal quotation, like you just did right there. If we're going to talk about strawmen...
someone would reply "hey, TurnTrout didn't actually say that stuff."
No one would say that or correct me for falsifying quotes, because I didn't say you said that stuff. They might (and some do) disagree with my sarcastic description, but they certainly weren't going to say 'gwern, TurnTrout never actually used the phrase "shocked and awed" or the word "crystallizing", how could you just make stuff up like that???' ...Because I didn't. So it seems unfair to judge LW and talk about how you are "not going to miss this site". (See what I did there? I am quoting you, which is why the text is in quotation marks, and if you didn't write that in the comment I am responding to, someone is probably going to ask where the quote is from. But they won't, because you did write that quote).
You know, local validity and all that. I'm really not going to miss this site.
In jumping to accusations of making up quotes and attacking an entire site for not immediately criticizing me in the way you are certain I should be criticized and saying that these failures illustrate why you are quitting it, might one say that you are being... overconfident?
Additionally, the anecdote was unrelated to the other section of my comment, so I didn't "feel" it was a "capstone."
Quite aside from it being in the same comment and so you felt it was related, it was obviously related to your first half about overconfidence in providing an anecdote of what you felt was overconfidence, and was rhetorically positioned at the end as the concrete Eliezer conclusion/illustration of the first half about abstract MIRI overconfidence. And you agree that that is what you are doing in your own description, that he "isn't deploying careful reasoning" in the large things as well as the small, and you are presenting it as a small self-contained story illustrating that general overconfidence:
Replies from: TurnTroutHowever, my actual experience is that Eliezer goes around doing things like e.g. impatiently interrupting people and being instantly wrong about it (importantly, in the realm of AI, as was the original context). This makes me think that Eliezer isn't deploying careful reasoning to begin with.
↑ comment by TurnTrout · 2024-12-31T20:08:39.032Z · LW(p) · GW(p)
I, uh, didn't say you "say" either of those
I wasn't claiming you were saying I had used those exact phrases.
Your original comment [LW(p) · GW(p)] implies that I expressed the sentiments for which you mocked me - such as the anecdote "crystallizing everything wrong about Eliezer" (the quotes are there because you said this). I then replied to point out that I did not, in fact, express those sentiments. Therefore, your mockery was invalid.
↑ comment by Adam Jermyn (adam-jermyn) · 2024-06-01T01:37:53.730Z · LW(p) · GW(p)
One day a mathematician doesn’t know a thing. The next day they do. In between they made no observations with their senses of the world.
It’s possible to make progress through theoretical reasoning. It’s not my preferred approach to the problem (I work on a heavily empirical team at a heavily empirical lab) but it’s not an invalid approach.
Replies from: TurnTrout↑ comment by TsviBT · 2024-06-02T10:21:00.629Z · LW(p) · GW(p)
I personally have updated a fair amount over time on
- people (going on) expressing invalid reasoning for their beliefs about timelines and alignment;
- people (going on) expressing beliefs about timelines and alignment that seemed relatively more explicable via explanations other than "they have some good reason to believe this that I don't know about";
- other people's alignment hopes and mental strategies have more visible flaws and visible doomednesses;
- other people mostly don't seem to cumulatively integrate the doomednesses of their approaches into their mental landscape as guiding elements;
- my own attempts to do so fail in a different way, namely that I'm too dumb to move effectively in the resulting modified landscape.
We can back out predictions of my personal models from this, such as "we will continue to not have a clear theory of alignment" or "there will continue to be consensus views that aren't supported by reasoning that's solid enough that it ought to produce that consensus if everyone is being reasonable".
↑ comment by Lukas_Gloor · 2024-06-01T14:28:15.966Z · LW(p) · GW(p)
I thought the first paragraph and the boldened bit of your comment seemed insightful. I don't see why what you're saying is wrong – it seems right to me (but I'm not sure).
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-06-01T16:16:28.624Z · LW(p) · GW(p)
(I didn't get anything out of it, and it seems kind of aggressive in a way that seems non-sequitur-ish, and also I am pretty sure mischaracterizes people. I didn't downvote it, but have disagree-voted with it)
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-05-31T18:56:03.286Z · LW(p) · GW(p)
I think you are abusing/misusing the concept of falsifiability here. Ditto for empiricism. You aren't the only one to do this, I've seen it happen a lot over the years and it's very frustrating. I unfortunately am busy right now but would love to give a fuller response someday, especially if you are genuinely interested to hear what I have to say (which I doubt, given your attitude towards MIRI).
Replies from: matthew-barnett, daniel-kokotajlo↑ comment by Matthew Barnett (matthew-barnett) · 2024-05-31T19:02:06.501Z · LW(p) · GW(p)
I unfortunately am busy right now but would love to give a fuller response someday, especially if you are genuinely interested to hear what I have to say (which I doubt, given your attitude towards MIRI).
I'm a bit surprised you suspect I wouldn't be interested in hearing what you have to say?
I think the amount of time I've spent engaging with MIRI perspectives over the years provides strong evidence that I'm interested in hearing opposing perspectives on this issue. I'd guess I've engaged with MIRI perspectives vastly more than almost everyone on Earth who explicitly disagrees with them as strongly as I do (although obviously some people like Paul Christiano and other AI safety researchers have engaged with them even more than me).
(I might not reply to you, but that's definitely not because I wouldn't be interested in what you have to say. I read virtually every comment-reply to me carefully, even if I don't end up replying.)
Replies from: daniel-kokotajlo, elityre, daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-05-31T20:26:28.871Z · LW(p) · GW(p)
I apologize, I shouldn't have said that parenthetical.
↑ comment by Eli Tyre (elityre) · 2024-06-20T04:18:09.304Z · LW(p) · GW(p)
I want to publicly endorse and express appreciation for Matthew's apparent good faith.
Every time I've ever seen him disagreeing about AI stuff on the internet (a clear majority of the times I've encountered anything he's written), he's always been polite, reasonable, thoughtful, and extremely patient. Obviously conversations sometimes entail people talking past each other, but I've seen him carefully try to avoid miscommunication, and (to my ability to judge) strawmanning.
Thank you Mathew. Keep it up. : )
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-06-01T12:08:30.407Z · LW(p) · GW(p)
Here's a new approach: Your list of points 1 - 7. Would you also make those claims about me? (i.e. replace references to MIRI with references to Daniel Kokotajlo.)
Replies from: matthew-barnett↑ comment by Matthew Barnett (matthew-barnett) · 2024-06-01T20:16:00.202Z · LW(p) · GW(p)
You've made detailed predictions about what you expect in the next several years, on numerous occasions, and made several good-faith attempts to elucidate your models of AI concretely. There are many ways we disagree, and many ways I could characterize your views, but "unfalsifiable" is not a label I would tend to use for your opinions on AI. I do not mentally lump you together with MIRI in any strong sense.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-06-02T12:30:07.628Z · LW(p) · GW(p)
OK, glad to hear. And thank you. :) Well, you'll be interested to know that I think of my views on AGI as being similar to MIRI's, just less extreme in various dimensions. For example I don't think literally killing everyone is the most likely outcome, but I think it's a very plausible outcome. I also don't expect the 'sharp left turn' to be particularly sharp, such that I don't think it's a particularly useful concept. I also think I've learned a lot from engaging with MIRI and while I have plenty of criticisms of them (e.g. I think some of them are arrogant and perhaps even dogmatic) I think they have been more epistemically virtuous than the average participant in the AGI risk conversation, even the average 'serious' or 'elite' participant.
Replies from: Will Aldred↑ comment by _will_ (Will Aldred) · 2024-10-30T04:08:35.013Z · LW(p) · GW(p)
I don't think [AGI/ASI] literally killing everyone is the most likely outcome
Huh, I was surprised to read this. I’ve imbibed a non-trivial fraction of your posts and comments here on LessWrong, and, before reading the above, my shoulder Daniel [LW · GW] definitely saw extinction as the most likely existential catastrophe.
If you have the time, I’d be very interested to hear what you do think is the most likely outcome. (It’s very possible that you have written about this before and I missed it—my bad, if so.)
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-10-30T04:15:19.945Z · LW(p) · GW(p)
(My model of Daniel thinks the AI will likely take over, but probably will give humanity some very small fraction of the universe, for a mixture of "caring a tiny bit" and game-theoretic reasons)
Replies from: Will Aldred↑ comment by _will_ (Will Aldred) · 2024-10-30T04:40:12.440Z · LW(p) · GW(p)
Thanks, that’s helpful!
(Fwiw, I don’t find the ‘caring a tiny bit’ story very reassuring, for the same reasons [LW · GW] as Wei Dai, although I do find the acausal trade story for why humans might be left with Earth somewhat heartening. (I’m assuming that by ‘game-theoretic reasons’ you mean acausal trade.))
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-10-30T16:59:36.995Z · LW(p) · GW(p)
Yep, Habryka is right. Also, I agree with Wei Dai re: reassuringness. I think literal extinction is <50% likely, but this is cold comfort given the badness of some of the plausible alternatives, and overall I think the probability of something comparably bad happening is >50%.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-06-18T14:22:35.307Z · LW(p) · GW(p)
Followup: Matthew and I ended up talking about it in person. tl;dr of my position is that
Falsifiability is a symmetric two-place relation; one cannot say "X is unfalsifiable," except as shorthand for saying "X and Y make the same predictions," and thus Y is equally unfalsifiable. When someone is going around saying "X is unfalsifiable, therefore not-X," that's often a misuse of the concept--what they should say instead is "On priors / for other reasons (e.g. deference) I prefer not-X to X; and since both theories make the same predictions, I expect to continue thinking this instead of updating, since there won't be anything to update on.
What is the point of falsifiability-talk then? Well, first of all, it's quite important to track when two theories make the same predictions, or the same-predictions-till-time-T. It's an important part of the bigger project of extracting predictions from theories so they can be tested. It's exciting progress when you discover that two theories make different predictions, and nail it down well enough to bet on. Secondly, it's quite important to track when people are making this worse rather than easier -- e.g. fortunetellers and pundits will often go out of their way to avoid making any predictions that diverge from what their interlocutors already would predict. Whereas the best scientists/thinkers/forecasters, the ones you should defer to, should be actively trying to find alpha and then exploit it by making bets with people around them. So falsifiability-talk is useful for evaluating people as epistemically virtuous or vicious. But note that if this is what you are doing, it's all a relative thing in a different way -- in the case of MIRI, for example, the question should be "Should I defer to them more, or less, than various alternative thinkers A B and C? --> Are they generally more virtuous about making specific predictions, seeking to make bets with their interlocutors, etc. than A B or C?"
So with that as context, I'd say that (a) It's just wrong to say 'MIRI's theories of doom are unfalsifiable.' Instead say 'unfortunately for us (not for the plausibility of the theories), both MIRI's doom theories and (insert your favorite non-doom theories here) make the same predictions until it's basically too late.' (b) One should then look at MIRI and be suspicious and think 'are they systematically avoiding making bets, making specific predictions, etc. relative to the other people we could defer to? Are they playing the sneaky fortuneteller or pundit's game?' to which I think the answer is 'no not at all, they are actually more epistemically virtuous in this regard than the average intellectual. That said, they aren't the best either -- some other people in the AI risk community seem to be doing better than them in this regard, and deserve more virtue points (and possibly deference points) therefore.' E.g. I think both Matthew and I have more concrete forecasting track records than Yudkowsky?
↑ comment by Martin Randall (martin-randall) · 2025-01-19T01:29:16.820Z · LW(p) · GW(p)
Falsifiability is not symmetric. Consider two theories:
- Theory X: Jesus will come again.
- Theory Y: Jesus will not come again.
If Jesus comes again tomorrow, this falsifies theory Y and confirms theory X. If Jesus does not come again tomorrow, neither theory is falsified or confirmed. So we can say that X is unfalsifiable (with respect to a finite time frame) and Y is falsifiable.
Another example:
- Theory X: blah blah and therefore the sky is green
- Theory Y: blah blah and therefore the sky is not green
- Theory Z: blah blah and therefore the sky could be green or not green.
Here, theory X and Y are falsifiable with respect to the color of the sky and theory Z is not.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-19T05:33:17.388Z · LW(p) · GW(p)
Here's how I'd deal with those examples:
Theory X: Jesus will come again: Presumably this theory assigns some probability mass >0 to observing Jesus tomorrow, whereas theory Y assigns ~0. If jesus is not observed tomorrow, that's a small amount of evidence for theory Y and a small amount of evidence against theory X. So you can say that theory X has been partially falsified. Repeat this enough times, and then you can say theory X has been fully falsified, or close enough. (Your credence in theory X will never drop to 0 probably, but that's fine, that's also true of all sorts of physical theories in good standing e.g. all the major theories of cosmology and cognitive science, which allow for tiny probabilities of arbitrary sequences of experiences happening in e.g. Boltzmann Brains)
With the sky color example:
My way of thinking about falsifiability is, we say two theories are falsifiable relative to each other if there is evidence we expect to encounter that will distinguish them / cause us to shift our relative credence in them.
In the case of Theory Z, there is an implicit theory Z2 which is "NOT blah blah, and therefore the sky could be green or not green." (Presumably that's what you are holding in the back of your mind as the alternative to Z, when you imagine updating for or against Z on the basis of seeing blue sky, and decide that you wouldn't?) Because the theory Z3 "NOT blah blah and therefore the sky is blue" would be confirmed by seeing a blue sky, and if somehow you were splitting your credence between Z and Z3, then you would decrease your credence in Z if you saw a blue sky.
↑ comment by Martin Randall (martin-randall) · 2025-01-19T18:14:29.718Z · LW(p) · GW(p)
Thanks for explaining. I think we have a definition dispute. Wikipedia:Falsifiability has:
A theory or hypothesis is falsifiable if it can be logically contradicted by an empirical test.
Whereas your definition is:
Falsifiability is a symmetric two-place relation; one cannot say "X is unfalsifiable," except as shorthand for saying "X and Y make the same predictions," and thus Y is equally unfalsifiable.
In one of the examples I gave earlier:
- Theory X: blah blah and therefore the sky is green
- Theory Y: blah blah and therefore the sky is not green
- Theory Z: blah blah and therefore the sky could be green or not green.
None of X, Y, or Z are Unfalsifiable-Daniel with respect to each other, because they all make different predictions. However, X and Y are Falsifiable-Wikipedia, whereas Z is Unfalsifiable-Wikipedia.
I prefer the Wikipedia definition. To say that two theories produce exactly the same predictions, I would instead say they are indistinguishable, similar to this Phyiscs StackExchange: Are different interpretations of quantum mechanics empirically distinguishable?.
In the ancestor post [LW(p) · GW(p)], Barnett writes:
MIRI researchers rarely provide any novel predictions about what will happen before AI doom, making their theories of doom appear unfalsifiable.
Barnett is using something like the Wikipedia definition of falsifiability here. It's unfair to accuse him of abusing or misusing the concept when he's using it in a very standard way.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-20T15:56:41.449Z · LW(p) · GW(p)
Very good point.
So, by the Wikipedia definition, it seems that all the mainstream theories of cosmology are unfalsifiable, because they allow for tiny probabilities of boltmann brains etc. with arbitrary experiences. There is literally nothing you could observe that would rule them out / logically contradict them.
Also, in practice, it's extremely rare for a theory to be ruled out or even close-to-ruled out from any single observation or experiment. Instead, evidence accumulates in a bunch of minor and medium-sized updates.
↑ comment by Martin Randall (martin-randall) · 2025-01-21T03:08:22.580Z · LW(p) · GW(p)
I think cosmology theories have to be phrased as including background assumptions like "I am not a Boltzmann brain" and "this is not a simulation" and such. Compare Acknowledging Background Information with P(Q|I) [LW · GW] for example. Given that, they are Falsifiable-Wikipedia.
I view Falsifiable-Wikipedia in a similar way to Occam's Razor. The true epistemology has a simplicity prior, and Occam's Razor is a shadow of that. The true epistemology considers "empirical vulnerability" / "experimental risk" to be positive. Possibly because it falls out of Bayesian updates, possibly because they are "big if true", possibly for other reasons. Falsifiability is a shadow of that.
In that context, if a hypothesis makes no novel predictions, and the predictions it makes are a superset of the predictions of other hypotheses, it's less empirically vulnerable, and in some relative sense "unfalsifiable", compared to those other hypotheses.
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2025-01-21T15:21:10.555Z · LW(p) · GW(p)
"this is not a simulation"
I personally wouldn't include it, because essentially everything (given a powerful enough model of computation) could be simulated, and this is why the simulation hypothesis is so bad in casual discourse: It explains everything, which means it explains nothing that is specific to our universe:
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-20T16:58:41.433Z · LW(p) · GW(p)
Also note that Barnett said "any novel predictions" which is not part of the wikipedia definition of falsifiability right? The wikipedia definition doesn't make reference to an existing community of scientists who already made predictions, such that a new hypothesis can be said to have made novel vs. non-novel predictions.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-20T17:00:58.972Z · LW(p) · GW(p)
I totally agree btw that it matters sociologically who is making novel predictions and who is sticking with the crowd. And I do in fact ding MIRI points for this relative to some other groups. However I think relative to most elite opinion-formers on AGI matters, MIRI performs better than average on this metric.
But note that this 'novel predictions' metric is about people/institutions, not about hypotheses.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-21T15:40:47.003Z · LW(p) · GW(p)
However I think relative to most elite opinion-formers on AGI matters, MIRI performs better than average on this metric.
Agree with this, with the caveat that I think all of their rightness relative to others fundamentally was in believing that short timelines were plausible enough, combined with believing in AI being the most major force of the 21st century by far, compared to other technologies, and basically a lot of their other specific predictions are likely to be pretty wrong.
I like this comment here about a useful comparison point to MIRI, where physicists were right about the higgs boson existing, but wrong on the theories like supersymmetry where people expected the higgs mass to be naturally stabilized, and assuming supersymmetry is correct for our universe, the theory cannot stabilize the mass of the higgs, or solve the hierarchy problem:
https://www.lesswrong.com/posts/ZLAnH5epD8TmotZHj/you-can-in-fact-bamboozle-an-unaligned-ai-into-sparing-your#Ha9hfFHzJQn68Zuhq [LW(p) · GW(p)]
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2025-01-21T17:53:02.334Z · LW(p) · GW(p)
I think I agree with this -- but do you see how it makes me frustrated to hear people dunk on MIRI's doomy views as unfalsifiable? Here's what happened in a nutshell:
MIRI: "AGI is coming and it will kill everyone."
Everyone else: "AGI is not coming and if it did it wouldn't kill everyone."
time passes, evidence accumulates...
Everyone else: "OK, AGI is coming, but it won't kill everyone"
Everyone else: "Also, the hypothesis that it won't kill everyone is unfalsifiable so we shouldn't believe it."
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-21T18:18:37.648Z · LW(p) · GW(p)
Yeah, I think this is actually a problem I see here, though admittedly I often see the hypotheses be vaguely formulated, and I kind of agree with Jotto999 that the verbal forecasts give far too much room for leeway here:
I like Eli Tyre's comment here:
https://www.lesswrong.com/posts/ZEgQGAjQm5rTAnGuM/beware-boasting-about-non-existent-forecasting-track-records#Dv7aTjGXEZh6ALmZn [LW(p) · GW(p)]
↑ comment by Martin Randall (martin-randall) · 2025-01-21T19:42:21.461Z · LW(p) · GW(p)
I like that metric, but the metric I'm discussing is more:
- Are they proposing clear hypotheses?
- Do their hypotheses make novel testable predictions?
- Are they making those predictions explicit?
So for example, looking at MIRI's very first blog post in 2007: The Power of Intelligence. I used the first just to avoid cherry-picking.
Hypothesis: intelligence is powerful. (yes it is)
This hypothesis is a necessary precondition for what we're calling "MIRI doom theory" here. If intelligence is weak then AI is weak and we are not doomed by AI.
Predictions that I extract:
- An AI can do interesting things over the Internet without a robot body.
- An AI can get money.
- An AI can be charismatic.
- An AI can send a ship to Mars.
- An AI can invent a grand unified theory of physics.
- An AI can prove the Riemann Hypothesis.
- An AI can cure obesity, cancer, aging, and stupidity.
Not a novel hypothesis, nor novel predictions, but also not widely accepted in 2007. As predictions they have aged very well, but they were unfalsifiable. If 2025 Claude had no charisma, it would not falsify the prediction that an AI can be charismatic.
I don't mean to ding MIRI any points here, relative or otherwise, it's just one blog post, I don't claim it supports Barnett's complaint by itself. I mostly joined the thread to defend the concept of asymmetric falsifiability.
↑ comment by Noosphere89 (sharmake-farah) · 2025-01-21T15:26:58.107Z · LW(p) · GW(p)
Martin Randall extracted the practical consequences of this here:
In that context, if a hypothesis makes no novel predictions, and the predictions it makes are a superset of the predictions of other hypotheses, it's less empirically vulnerable, and in some relative sense "unfalsifiable", compared to those other hypotheses.
↑ comment by ryan_greenblatt · 2024-05-30T23:51:48.912Z · LW(p) · GW(p)
I basically agree with your overall comment, but I'd like to push back in one spot:
If your model of reality has the power to make these sweeping claims with high confidence
From my understanding, for at least Nate Soares, he claims his internal case for >80% doom is disjunctive and doesn't route all through 1, 2, 3, and 4.
I don't really know exactly what the disjuncts are, so this doesn't really help and I overall agree that MIRI does make "sweeping claims with high confidence".
↑ comment by Jeremy Gillen (jeremy-gillen) · 2024-05-31T23:51:54.457Z · LW(p) · GW(p)
I think your summary is a good enough quick summary of my beliefs. The minutia that I object to is how confident and specific lots of parts of your summary are. I think many of the claims in the summary can be adjusted or completely changed and still lead to bad outcomes. But it's hard to add lots of uncertainty and options to a quick summary, especially one you disagree with, so that's fair enough.
(As a side note, that paper you linked isn't intended to represent anyone else's views, other than myself and Peter, and we are relatively inexperienced. I'm also no longer working at MIRI).
I'm confused about why your <20% isn't sufficient for you to want to shut down AI research. Is it because of benefits outweigh the risk, or because we'll gain evidence about potential danger and can shut down later if necessary?
I'm also confused about why being able to generate practical insights about the nature of AI or AI progress is something that you think should necessarily follow from a model that predicts doom. I believe something close enough to (1) from your summary, but I don't have much idea (above general knowledge) of how the first company to build such an agent will do so, or when they will work out how to do it. One doesn't imply the other.
↑ comment by Matthew Barnett (matthew-barnett) · 2024-06-01T00:15:46.101Z · LW(p) · GW(p)
I'm confused about why your <20% isn't sufficient for you to want to shut down AI research. Is it because of benefits outweigh the risk, or because we'll gain evidence about potential danger and can shut down later if necessary?
I think the expected benefits outweigh the risks, given that I care about the existing generation of humans (to a large, though not overwhelming degree). The expected benefits here likely include (in my opinion) a large reduction in global mortality, a very large increase in the quality of life, a huge expansion in material well-being, and more generally a larger and more vibrant world earlier in time. Without AGI, I think most existing people would probably die and get replaced by the next generation of humans, in a relatively much poor world (compared to the alternative).
I also think the absolute level risk from AI barely decreases if we globally pause. My best guess is that pausing would mainly just delay adoption without significantly impacting safety. Under my model of AI, the primary risks are long-term, and will happen substantially after humans have already gradually "handed control" over to the AIs and retired their labor on a large scale. Most of these problems -- such as cultural drift and evolution -- do not seem to be the type of issue that can be satisfactorily solved in advance, prior to a pause (especially by working out a mathematical theory of AI, or something like that).
On the level of analogy, I think of AI development as more similar to "handing off control to our children" than "developing a technology that disempowers all humans at a discrete moment in time". In general, I think the transition period to AI will be more diffuse and incremental than MIRI seems to imagine, and there won't be a sharp distinction between "human values" and "AI values" either during, or after the period.
(I also think AIs will probably be conscious in a way that's morally important, in case that matters to you.)
In fact, I think it's quite plausible the absolute level of AI risk would increase under a global pause, rather than going down, given the high level of centralization of power required to achieve a global pause, and the perverse institutions and cultural values that would likely arise under such a regime of strict controls. As a result, even if I weren't concerned at all about the current generation of humans, and their welfare, I'd still be pretty hesitant to push pause on the entire technology.
(I think of technology as itself being pretty risky, but worth it. To me, pushing pause on AI is like pushing pause on technology itself, in the sense that they're both generically risky yet simultaneously seem great on average. Yes, there are dangers ahead. But I think we can be careful and cautious without completely ripping up all the value for ourselves.)
Replies from: Lukas_Gloor, quetzal_rainbow, dr_s↑ comment by Lukas_Gloor · 2024-06-01T13:54:05.057Z · LW(p) · GW(p)
Would most existing people accept a gamble with 20% of chance of death in the next 5 years and 80% of life extension and radically better technology? I concede that many would, but I think it's far from universal, and I wouldn't be too surprised if half of people or more think this isn't for them.
I personally wouldn't want to take that gamble (strangely enough I've been quite happy lately and my life has been feeling meaningful, so the idea of dying in the next 5 years sucks).
(Also, I want to flag that I strongly disagree with your optimism.)
↑ comment by Matthew Barnett (matthew-barnett) · 2024-06-01T17:52:30.467Z · LW(p) · GW(p)
For what it's worth, while my credence in human extinction from AI in the 21st century is 10-20%, I think the chance of human extinction in the next 5 years is much lower. I'd put that at around 1%. The main way I think AI could cause human extinction is by just generally accelerating technology and making the world a scarier and more dangerous place to live. I don't really buy the model in which an AI will soon foom until it becomes a ~god.
↑ comment by Seth Herd · 2024-06-01T17:04:55.388Z · LW(p) · GW(p)
I like this framing. I think the more common statement would be 20% chance of death in 10-30 years , and 80% chance of life extension and much better technology that they might not live to see.
I think the majority of humanity would actually take this bet. They are not utilitarians or longtermists.
So if the wager is framed in this way, we're going full steam ahead.
↑ comment by quetzal_rainbow · 2024-06-01T08:26:25.404Z · LW(p) · GW(p)
I yet another time say that your tech tree model doesn't make sense to me. To get immortality/mind uploading, you need really overpowered tech, far above the level when killing all humans and starting disassemble planet becomes negligibly cheap. So I wouldn't expect that "existing people would probably die" is going to change much under your model "AIs can be misaligned but killing all humans is too costly".
↑ comment by dr_s · 2024-06-03T09:24:46.616Z · LW(p) · GW(p)
(I also think AIs will probably be conscious in a way that's morally important, in case that matters to you.)
I don't think that's either a given nor something we can ever know for sure. "Handing off" the world to robots and AIs that for all we know might be perfect P-zombies doesn't feel like a good idea.
↑ comment by Signer · 2024-06-01T08:04:20.128Z · LW(p) · GW(p)
Given a low prior probability of doom as apparent from the empirical track record of technological progress, I think we should generally be skeptical of purely theoretical arguments for doom, especially if they are vague and make no novel, verifiable predictions prior to doom.
And why such use of the empirical track record is valid? Like, what's the actual hypothesis here? What law of nature says "if technological progress hasn't caused doom yet, it won't cause it tomorrow"?
MIRI’s arguments for doom are often difficult to pin down, given the informal nature of their arguments, and in part due to their heavy reliance on analogies, metaphors, and vague supporting claims instead of concrete empirically verifiable models.
And arguments against are based on concrete empirically verifiable models of metaphors.
If your model of reality has the power to make these sweeping claims with high confidence, then you should almost certainly be able to use your model of reality to make novel predictions about the state of the world prior to AI doom that would help others determine if your model is correct.
Doesn't MIRI's model predict some degree of the whole Shoggoth/actress thing in current system? Seems verifiable.
↑ comment by Seth Herd · 2024-06-01T17:19:51.015Z · LW(p) · GW(p)
I share your frustration with MIRI's communications with the alignment community.
And, the tone of this comment smells to me of danger. It looks a little too much like strawmanning, which always also implies that anyone who believes this scenario must be, at least in this context, an idiot. Since even rationalists are human, this leads to arguments instead of clarity.
I'm sure this is an accident born of frustration, and the unclarity of the MIRI argument.
I think we should prioritize not creating a polarized doomer-vs-optimist split in the safety community. It is very easy to do, and it looks to me like that's frequently how important movements get bogged down.
Since time is of the essence, this must not happen in AI safety.
We can all express our views, we just need to play nice and extend the benefit of the doubt. MIRI actually does this quite well, although they don't convey their risk model clearly. Let's follow their example in the first and not the second.
Edit: I wrote a short form post about MIRI's communication strategy [LW(p) · GW(p)], including how I think you're getting their risk model importantly wrong
↑ comment by Ebenezer Dukakis (valley9) · 2024-06-05T03:17:13.459Z · LW(p) · GW(p)
Eliezer's response to claims about unfalsifiability, namely that "predicting endpoints is easier than predicting intermediate points", seems like a cop-out to me, since this would seem to reverse the usual pattern in forecasting and prediction, without good reason.
Note that MIRI has made some intermediate predictions. For example, I'm fairly certain Eliezer predicted that AlphaGo would go 5 for 5 against LSD, and it didn't. I would respect his intellectual honesty more if he'd registered the alleged difficulty of intermediate predictions before making them unsuccessfully.
I think MIRI has something valuable to contribute to alignment discussions, but I'd respect them more if they did a "5 Whys" type analysis on their poor prediction track record, so as to improve the accuracy of predictions going forwards. I'm not seeing any evidence of that. It seems more like the standard pattern where a public figure invests their ego in some position, then tries to avoid losing face.
↑ comment by Joe Collman (Joe_Collman) · 2024-06-02T05:06:50.609Z · LW(p) · GW(p)
On your (2), I think you're ignoring an understanding-related asymmetry:
- Without clear models describing (a path to) a solution, it is highly unlikely we have a workable solution to a deep and complex problem:
- Absence of concrete [we have (a path to) a solution] is pretty strong evidence of absence.
[EDIT for clarity, by "we have" I mean "we know of", not "there exists"; I'm not claiming there's strong evidence that no path to a solution exists]
- Absence of concrete [we have (a path to) a solution] is pretty strong evidence of absence.
- Whether or not we have clear models of a problem, it is entirely possible for it to exist and to kill us:
- Absence of concrete [there-is-a-problem] evidence is weak evidence of absence.
A problem doesn't have to wait until we have formal arguments or strong, concrete empirical evidence for its existence before killing us. To claim that it's "premature" to shut down the field before we have [evidence of type x], you'd need to make a case that [doom before we have evidence of type x] is highly unlikely.
A large part of the MIRI case is that there is much we don't understand, and that parts of the problem we don't understand are likely to be hugely important. An evidential standard that greatly down-weights any but the most rigorous, legible evidence is liable to lead to death-by-sampling-bias.
Of course it remains desirable for MIRI arguments to be as legible and rigorous as possible. Empiricism would be nice too (e.g. if someone could come up with concrete problems whose solution would be significant evidence for understanding something important-according-to-MIRI about alignment).
But ignoring the asymmetry here is a serious problem.
On your (3), it seems to me that you want "skeptical" to do more work than is reasonable. I agree that we "should be skeptical of purely theoretical arguments for doom" - but initial skepticism does not imply [do not update much on this]. It implies [consider this very carefully before updating]. It's perfectly reasonable to be initially skeptical but to make large updates once convinced.
I do not think [the arguments are purely theoretical] is one of your true objections - rather it's that you don't find these particular theoretical arguments convincing. That's fine, but no argument against theoretical arguments.
↑ comment by VojtaKovarik · 2024-06-07T02:34:01.422Z · LW(p) · GW(p)
tl;dr: "lack of rigorous arguments for P is evidence against P" is typically valid, but not in case of P = AI X-risk.
A high-level reaction to your point about unfalsifiability:
There seems to be a general sentiment that "AI X-risk arguments are unfalsifiable ==> the arguments are incorrect" and "AI X-risk arguments are unfalsifiable ==> AI X-risk is low".[1] I am very sympathetic to this sentiment --- but I also think that in the particular case of AI X-risk, it is not justified.[2] For quite non-obvious reasons.
Why I believe this?
Take this simplified argument for AI X-risk:
- Some important future AIs will be goal-oriented, or will behave in a goal-oriented way in sometimes[3]. (Read: If you think of them as trying to maximise some goal, you will make pretty good predictions.[4])
- The "AI-progress tech-tree" is such that discontinous jumps in impact are possible. In particular, we will one day go from "an AI that is trying to maximise some goal, but not doing a very good job of it" to "an AI that is able to treat humans and other existing AIs as 'environment', and is going to do a very good job at maximising some goal".
- For virtually any[5] goal specification, doing a sufficiently[6] good job at maximising that goal specification leads to an outcome where every human is dead.
FWIW, I think that having a strong opinion on (1) and (2), in either direction, is not justified.[7] But in this comment, I only want to focus on (3) --- so let's please pretend, for the sake of this discussion, that we find (1) and (2) at least plausible. What I claim is that even if we lived in a universe where (3) is true, we should still expect even the best arguments for (3) (that we might realistically identify) to be unfalsifiable --- at least given realistic constraints on falsification effort and assumming that we use rigorous standards for what counts as a solid evidence, like people do in mathematics, physics, or CS.
What is my argument for "even best arguments for (3) will be unfalsifiable"?
Suppose you have an environment that contains a Cartesian agent (a thing that takes actions in the environment and -- let's assume for simplicity -- has perfect information about the environment, but whose decison-making computation happens outside of the environment). And suppose that this agent acts in a way that maximises[8] some goal specification[9] over . Now, might or might not contain humans, or representations of humans. We can now ask the following question: Is it true that, unless we spend an extremely high amont of effort (eg, >5 civilisation-years), any (non-degenerate[10]) goal-specification we come up with will result in human extinction[11] in E when maximised by the agent. I refer to this as "Extinction-level Goodhart's Law [LW · GW]".
I claim that:
(A) Extinction-level Goodhart's Law plausibly holds in the real world. (At least the thought expertiments I know, eg here [LW · GW] or here, of suggest it does.)
(B) Even if Extinction-level Goodhart's Law was true in the real world, it would still be false in environments where we could verify it experimentally (today, or soon) or mathematically (by proofs, given realistic amounts of effort).
==> And (B) implies that if we want "solid arguments", rather than just thought expertiments, we might be kinda screwed when it comes to Extinction-level Goodhart's Law.
And why do I believe (B)? The long story is that I try to gesture at this in my sequence on "Formalising Catastrophic Goodhart [? · GW]". The short story is that there are many strategies for finding "safe to optimise" goal specifications that work in simpler environments, but not in the real-world (examples below). So to even start gaining evidence on whether the law holds in our world, we need to investigate envrionments where those simpler strategies don't work --- and it seems to me that those are always too complex for us to analyse mathematically or run an AI there which could "do a sufficiently good job a trying to maximise the goal specification".
Some examples of the above-mentioned strategies for finding safe-to-optimise goal specifications: (i) The environment contains no (representations of) humans, or those "humans" can't "die", so it doesn't matter. EG, most gridworlds. (ii) The environment doesn't have any resources or similar things that would give rise to convergent instrumental goals, so it doesn't matter. EG, most gridworlds. (iii) The environment allows for a simple formula that checks whether "humans" are "extinct", so just add a huge penalty if that formula holds. (EG, most gridworlds where you added "humans".) (iv) There is a limited set of actions that result in "killing" "humans", so just add a huge penalty to those. (v) There is a simple formula for expressing a criterion that limits the agent's impact. (EG, "don't go past these coordinates" in a gridworld.)
All together, this should explain why the "unfalsifiability" counter-argument does not hold as much weight, in the case of AI X-risk, as one might intuitively expect.
- ^
If I understand you correctly, you would endorse something like this? Quite possibly with some disclaimers, ofc. (Certainly I feel that many other people endorse something like this.)
- ^
I acknowledge that the general heuristic "argument for X is unfalsifiable ==> the argument is wrong" holds in most cases. And I am aware we should be sceptical whenever somebody goes "but my case is an exception!". Despite this, I still believe that AI X-risk genuinely is different from invisible dragons in your garage [LW · GW] and conspiracy theories.
That said, I feel there should be a bunch of other examples where the heuristic doesn't apply. If you have some that are good, please share! - ^
An example of this would be if GPT-4 acted like a chatbot most of the time, but tried to take over the world if you prompt it with "act as a paperclipper".
- ^
And this way of thinking about them is easier -- description length, etc -- than other options. EG, no "water bottles maximising being a water battle".
- ^
By "virtual any" goal specification (leading to extinction when maximised), I mean that finding a goal specification for which extinction does not happen (when maximised) is extremely difficult. One example of operationalising "extremely difficult" would be "if our civilisation spent all its efforts on trying to find some goal specification, for 5 years from today, we would still fail". In particular, the claim (3) is meant to imply that if you do anything like "do RLHF for a year, then optimise the result extremely hard", then everybody dies.
- ^
For the purposes of this simplified AI X-risk argument, the AIs from (2), which are "very good at maximising a goal", are meant to qualify for the "sufficiently good job at maximising a goal" from (3). In practice, this is of course more complicated --- see e.g. my post on Weak vs Quantitative Extinction-level Goodhart's Law [LW · GW].
- ^
Or at least there are no publicly available writings, known to me, which could justifiy claims like "It's >=80% likely that (1) (or 2) holds (or doesn't hold)". Of course, (1) and (2) are too vague for this to even make sense, but imagine replacing (1) and (2) by more serious attempts at operationalising the ideas that they gesture at.
- ^
(or does a sufficiently good job of maximising)
- ^
Most reasonable ways of defining what "goal specification" means should work for the argument. As a simple example, we can think of having a reward function R : states --> R and maximising the sum of R(s) over any long time horizon.
- ^
To be clear, there are some trivial ways of avoiding Extinction-level Goodhart's Law. One is to consider a constant utility function, which means that the agent might as well take random actions. Another would be to use reward functions in the spirit of "shut down now, or get a huge penalty". And there might be other weird edge cases.
I acknowledge that this part should be better developed. But in the meantime, hopefully it is clear -- at least somewhat -- what I am trying to gesture at. - ^
Most environments won't contain actual humans. So by "human extinction", I mean the "metaphorical humans being metaphorically dead". EG, if your environment was pacman, then the natural thing would be to view the pacman as representing a "human", and being eaten by the ghosts as representing "extinction". (Not that this would be a good model for studying X-risk.)
↑ comment by VojtaKovarik · 2024-06-07T02:35:09.780Z · LW(p) · GW(p)
FWIW, I acknowledge that my presentation of the argument isn't ironclad, but I hope that it makes my position a bit clearer. If anybody has ideas for how to present it better, or has some nice illustrative examples, I would be extremely grateful.
↑ comment by VojtaKovarik · 2024-06-07T02:54:09.819Z · LW(p) · GW(p)
An illustrative example, describing a scenario that is similar to our world, but where "Extinction-level Goodhart's law" would be false & falsifiable (hat tip Vincent Conitzer):
Suppose that we somehow only start working on AGI many years from now, after we have already discovered a way to colonize the universe at the close to the speed of light. And some of the colonies are already unreachable, outside of our future lightcone. But suppose we still understand "humanity" as the collection of all humans, including those in the unreachable colonies. Then any AI that we build, no matter how smart, would be unable to harm these portions of humanity. And thus full-blown human extinction, from AI we build here on Earth, would be impossible. And you could "prove" this using a simple, yet quite rigorous, physics argument.[1]
(To be clear, I am not saying that "AI X-risk's unfalsifiability is justifiable ==> we should update in favour of AI X-risk compared to our priors". I am just saying that the justifiability means we should not update against it compared to our priors. Though I guess that in practice, it means that some people should undo some of their updates against AI X-risk... )
- ^
And sure, maybe some weird magic is actually possible, and the AI could actually beat speed of light. But whatever, I am ignoring this, and an argument like this would count as falsification as far as I am concerned.
comment by johnswentworth · 2024-05-29T21:42:37.030Z · LW(p) · GW(p)
A thing I am confused about: what is the medium-to-long-term actual policy outcome you're aiming for? And what is the hopeful outcome which that policy unlocks?
You say "implement international AI compute governance frameworks and controls sufficient for halting the development of any dangerous AI development activity, and streamlined functional processes for doing so". The picture that brings to my mind is something like:
- Track all compute centers large enough for very high-flop training runs
- Put access controls in place for such high-flop runs
A prototypical "AI pause" policy in this vein would be something like "no new training runs larger than the previous largest run".
Now, the obvious-to-me shortcoming of that approach is that algorithmic improvement is moving at least as fast as scaling [LW · GW], a fact which I doubt Eliezer or Nate have overlooked. Insofar as that algorithmic improvement is itself compute-dependent, it's mostly dependent on small test runs rather than big training runs, so a pause-style policy would slow down the algorithmic component of AI progress basically not-at-all. So whatever your timelines look like, even a full pause on training runs larger than the current record should less than double our time.
... and that still makes implementation of a pause-style policy a very worthwhile thing for a lot of people to work on, but I'm somewhat confused that Eliezer and Nate specifically currently see that as their best option? Where is the hope here? What are they hoping happens with twice as much time, which would not happen with one times as much time? Or is there some other policy target (including e.g. "someone else figures out a better policy") which would somehow buy a lot more time?
Replies from: gretta-duleba, rhollerith_dot_com, Lblack↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-29T22:52:22.194Z · LW(p) · GW(p)
I don't speak for Nate or Eliezer in this reply; where I speak about Eliezer I am of course describing my model of him, which may be flawed.
Three somewhat disjoint answers:
- From my perspective, your point about algorithmic improvement only underlines the importance of having powerful people actually get what the problem is and have accurate working models. If this becomes true, then the specific policy measures have some chance of adapting to current conditions, or of being written in an adaptive manner in the first place.
- Eliezer said a few years ago that "I consider the present gameboard to look incredibly grim" and while he has more hope now than he had then about potential political solutions, it is not the case (as I understand it) that he now feels hopeful that these solutions will work. Our policy proposals are an incredible longshot.
- One thing we can hope for, if we get a little more time rather than a lot more time, is that we might get various forms of human cognitive enhancement working, and these smarter humans can make more rapid progress on AI alignment.
↑ comment by Seth Herd · 2024-05-30T03:20:26.135Z · LW(p) · GW(p)
It seems like including this in the strategy statement is crucial to communicating that strategy clearly (at least to people who understand enough of the background). A long-shot strategy looks very different from one where you expect to achieve at least useful parts of your goals.
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T15:23:50.361Z · LW(p) · GW(p)
A reasonable point, thank you. We said it pretty clearly in the MIRI strategy post in January, and I linked to that post here, but perhaps I should have reiterated it.
For clarity: we mostly just expect to die. But while we can see viable paths forward at all, we'll keep trying not to.
↑ comment by aog (Aidan O'Gara) · 2024-05-31T17:55:54.345Z · LW(p) · GW(p)
Has MIRI considered supporting work on human cognitive enhancement? e.g. Foresight's work on WBE.
↑ comment by RHollerith (rhollerith_dot_com) · 2024-05-31T01:36:37.967Z · LW(p) · GW(p)
These next changes implemented in the US, Europe and East Asia would probably buy us many decades:
Close all the AI labs and return their assets to their shareholders;
Require all "experts" (e.g., researchers, instructors) in AI to leave their jobs; give them money to compensate them for their temporary loss of earnings power;
Make it illegal to communicate technical knowledge about machine learning or AI; this includes publishing papers, engaging in informal conversations, tutoring, talking about it in a classroom; even distributing already-published titles on the subject gets banned.
Of course it is impractical to completely stop these activities (especially the distribution of already-published titles), but we do not have to completely stop them; we need only sufficiently reduce the rate at which the AI community worldwide produces algorithmic improvements. Here we are helped by the fact that figuring out how to create an AI capable of killing us all is probably still a very hard research problem.
What is most dangerous about the current situation is the tens of thousands of researchers world-wide with tens of billions in funding who feel perfectly free to communicate and collaborate with each other and who expect that they will be praised and rewarded for increasing our society's ability to create powerful AIs. If instead they come to expect more criticism than praise and more punishment than reward, most of them will stop -- and more importantly almost no young person is going to put in the years of hard work needed to become an AI researcher.
I know how awful this sounds to many of the people reading this, including the person I am replying to, but you did ask, "Is there some other policy target which would somehow buy a lot more time?"
Replies from: johnswentworth↑ comment by johnswentworth · 2024-05-31T16:44:44.283Z · LW(p) · GW(p)
I know how awful this sounds to many of the people reading this, including the person I am replying to...
I actually find this kind of thinking quite useful. I mean, the particular policies proposed are probably pareto-suboptimal, but there's a sound method in which we first ask "what policies would buy a lot more time?", allowing for pretty bad policies as a first pass, and then think through how to achieve the same subgoals in more palatable ways.
Replies from: rhollerith_dot_com↑ comment by RHollerith (rhollerith_dot_com) · 2024-06-01T18:32:40.320Z · LW(p) · GW(p)
>I actually find this kind of thinking quite useful
I'm glad.
↑ comment by Lucius Bushnaq (Lblack) · 2024-05-30T22:43:43.503Z · LW(p) · GW(p)
If there's a legal ceiling on AI capabilities, that reduces the short term economic incentive to improve algorithms. If improving algorithms gets you categorised as uncool at parties, that might also reduce the short term incentive to improve algorithms.
It is thus somewhat plausible to me that an enforced legal limit on AI capabilities backed by high-status-cool-party-attending-public opinion would slow down algorithmic progress significantly.
comment by Soapspud · 2024-05-29T20:19:43.022Z · LW(p) · GW(p)
We understand that we may be discounted or uninvited in the short term, but meanwhile our reputation as straight shooters with a clear and uncomplicated agenda remains intact.
I don't have any substantive comments, but I do want to express a great deal of joy about this approach.
I am really happy to see people choosing to engage with the policy, communications, and technical governance space with this attitude.
comment by jessicata (jessica.liu.taylor) · 2024-05-30T02:43:35.030Z · LW(p) · GW(p)
You want to shut down AI to give more time... for what? Let's call the process you want to give more time to X. You want X to go faster than AI. It seems the relevant quantity is the ratio between the speed of X and the speed of AI. If X could be clarified, it would make it more clear how efficient it is to increase this ratio by speeding up X versus by slowing down AI. I don't see in this post any idea of what X is, or any feasibility estimate of how easy it is to speed up X versus slowing down AI.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T02:57:47.478Z · LW(p) · GW(p)
Quoting from Gretta [LW(p) · GW(p)]:
Replies from: jessica.liu.taylor, ozziegooenOne thing we can hope for, if we get a little more time rather than a lot more time, is that we might get various forms of human cognitive enhancement working, and these smarter humans can make more rapid progress on AI alignment.
↑ comment by jessicata (jessica.liu.taylor) · 2024-05-30T03:02:02.760Z · LW(p) · GW(p)
Glad there is a specific idea there. What are the main approaches for this? There's Neuralink and there's gene editing, among other things. It seems MIRI may have access to technical talent that could speed up some of these projects.
Replies from: MathieuRoy, rhollerith_dot_com↑ comment by RHollerith (rhollerith_dot_com) · 2024-05-31T00:53:34.677Z · LW(p) · GW(p)
If we manage to avoid extinction for a few centuries, cognitive capacities among the most capable people are likely to increase substantially merely through natural selection. Because our storehouse of potent knowledge is now so large and because of other factors (e.g., increased specialization in the labor market), it is easier than ever for people with high cognitive capacity to earn above-average incomes and to avoid or obtain cures for illnesses of themselves and their children. (The level of health care a person can obtain by consulting doctors and being willing to follow their recommendations will always lag behind the level that can be obtained by doing that and doing one's best to create and refine a mental model of the illness.)
Yes, there is a process that has been causing the more highly-educated and the more highly-paid to have fewer children than average, but natural selection will probably cancel out the effect of that process over the next few centuries: I can't think of any human traits subject to more selection pressure than the traits that make it more likely the individual will choose to have children even when effective contraception is cheap and available. Also, declining birth rates are causing big problems for the economies and military readiness of many countries, and governments might in the future respond to those problems by banning contraception.
↑ comment by ozziegooen · 2024-06-01T18:01:00.188Z · LW(p) · GW(p)
Minor flag, but I've thought about some similar ideas, and here's one summary:
https://forum.effectivealtruism.org/posts/YpaQcARgLHFNBgyGa/prioritization-research-for-advancing-wisdom-and [EA · GW]
Personally, I'd guess that we could see a lot of improvement by clever uses of safe AIs. Even if we stopped improving on LLMs today, I think we have a long way to go to make good use of current systems.
Just because there are potentially risky AIs down the road doesn't mean we should ignore the productive use of safe AIs.
comment by Orpheus16 (akash-wasil) · 2024-05-30T01:04:30.672Z · LW(p) · GW(p)
Thank you for this update—I appreciate the clear reasoning. I also personally feel that the AI policy community is overinvested in the "say things that will get you points" strategy and underinvested in the "say true things that help people actually understand the problem" strategy. Specifically, I feel like many US policymakers have heard "be scared of AI because of bioweapons" but have not heard clear arguments about risks from autonomous systems, misalignment, AI takeover, etc.
A few questions:
- To what extent is MIRI's comms team (or technical governance team) going to interact directly with policymakers and national security officials? (I personally suspect you will be more successful if you're having regular conversations with your target audience and taking note of what points they find confusing or unconvincing rather than "thinking from first principles" about what points make a sound argument.)
- To what extent is MIRI going to contribute to concrete policy proposals (e.g., helping offices craft legislation or helping agencies craft specific requests)?
- To what extent is MIRI going to help flesh out how its policy proposals could be implemented? (e.g., helping iron out the details of what a potential international AI compute governance regime would look like, how it would be implemented, how verification would work, what society would do with the time it buys)
- Suppose MIRI has an amazing resource about AI risks. How does MIRI expect to get national security folks and important policymakers to engage with it?
(Tagging @lisathiergart [LW · GW] in case some of these questions overlap with the work of the technical governance team.)
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T15:26:04.564Z · LW(p) · GW(p)
All of your questions fall under Lisa's team and I will defer to her.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-05-30T15:34:40.644Z · LW(p) · GW(p)
Got it– thank you! Am I right in thinking that your team intends to influence policymakers and national security officials, though? If so, I'd be curious to learn more about how you plan to get your materials in front of them or ensure that your materials address their core points of concern/doubt.
Put a bit differently– I feel like it would be important for your team to address these questions insofar as your team has the following goals:
Replies from: gretta-dulebaThe main audience we want to reach is policymakers – the people in a position to enact the sweeping regulation and policy we want – and their staff.
We are hopeful about reaching a subset of policy advisors who have the skill of thinking clearly and carefully about risk, particularly those with experience in national security.
↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T15:51:03.938Z · LW(p) · GW(p)
In this reply I am speaking just about the comms team and not about other parts of MIRI or other organizations.
We want to produce materials that are suitable and persuasive for the audiences I named. (And by persuasive, I don't mean anything manipulative or dirty; I just mean using valid arguments that address the points that are most interesting / concerning to our audience in a compelling fashion.)
So there are two parts here: creating high quality materials, and delivering them to that audience.
First, creating high quality materials. Some of this is down to just doing a good job in general: making the right arguments in the right order using good writing and pedagogical technique; none of this is very audience specific. There is also an audience-specific component, and to do well on that, we do need to understand our audience better. We are working to recruit beta readers from appropriate audience pools.
Second, delivering them to those audiences. There are several approaches here, most of which will not be executed by the comms team directly, we hand off to others. Within comms, we do want to see good reach and engagement with intelligent general audiences.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-05-30T16:06:36.143Z · LW(p) · GW(p)
Thank you! I still find myself most curious about the "how will MIRI make sure it understands its audience" and "how will MIRI make sure its materials are read by policymakers + natsec people" parts of the puzzle. Feel free to ignore this if we're getting too in the weeds, but I wonder if you can share more details about either of these parts.
There is also an audience-specific component, and to do well on that, we do need to understand our audience better. We are working to recruit beta readers from appropriate audience pools.
Replies from: gretta-dulebaThere are several approaches here, most of which will not be executed by the comms team directly, we hand off to others
↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T16:10:47.886Z · LW(p) · GW(p)
Your curiosity and questions are valid but I'd prefer not to give you more than I already have, sorry.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-05-30T16:15:09.421Z · LW(p) · GW(p)
Valid!
comment by Zach Stein-Perlman · 2024-05-30T01:26:43.711Z · LW(p) · GW(p)
What are the best things—or some good things—MIRI comms has done or published in 2024?
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T15:30:00.330Z · LW(p) · GW(p)
At the start of 2024, the comms team was only me and Rob. We hired Harlan in Q1 and Joe and Mitch are only full time as of this week. Hiring was extremely labor-intensive and time consuming. As such, we haven't kicked into gear yet.
The main publicly-visible artifact we've produced so far is the MIRI newsletter; that comes out monthly.
Most of the rest of the object-level work is not public yet; the artifacts we're producing are very big and we want to get them right.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-05-30T15:42:03.558Z · LW(p) · GW(p)
the artifacts we're producing are very big and we want to get them right.
To the extent that this can be shared– What are the artifacts you're most excited about, and what's your rough prediction about when they will be ready?
Moreover, how do you plan to assess the success/failure of your projects? Are there any concrete metrics you're hoping to achieve? What does a "really good outcome" for MIRI's comms team look like by the end of the year, and what does a "we have failed and need to substantially rethink our approach, speed, or personnel" outcome look like?
(I ask partially because one of my main uncertainties right now is how well MIRI will get its materials in front of the policymakers and national security officials you're trying to influence. In the absence of concrete goals/benchmarks/timelines, I could imagine a world where MIRI moves at a relatively slow pace, produces high-quality materials with truthful arguments, but this content isn't getting to the target audience, and the work isn't being informed by the concerns/views of the target audience.)
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T16:04:55.871Z · LW(p) · GW(p)
What are the artifacts you're most excited about, and what's your rough prediction about when they will be ready?
Due to bugs in human psychology, we are more likely to succeed in our big projects if we don't yet state publicly what we're going to do by when. Sorry. I did provide some hints in the main post (website, book, online reference).
how do you plan to assess the success/failure of your projects? Are there any concrete metrics you're hoping to achieve? What does a "really good outcome" for MIRI's comms team look like by the end of the year,
The only concrete metric that really matters is "do we survive" but you are probably interested some intermediate performance indicators. :-P
The main things I am looking for within 2024 are not as SMART-goal shaped as you are probably asking for. What I'd like to see is that that we've developed enough trust in our most recent new hires that they are freely able to write on behalf of MIRI without getting important things wrong, such that we're no longer bottlenecked on a few key people within MIRI; that we're producing high-quality content at a much faster clip; that we have the capacity to handle many more of the press inquiries we receive rather than turning most of them down; that we're better positioned to participate in the 'wave' shaped current event conversations.
I'd like to see strong and growing engagement with the new website.
And probably most importantly, when others in our network engage in policy conversations, I'd like to hear reports back that our materials were useful.
what does a "we have failed and need to substantially rethink our approach, speed, or personnel" outcome look like?
Failure looks like: still bottlenecked on specific people, still drowning in high-quality press requests that we can't fulfill even though we'd like to, haven't produced anything, book project stuck in a quagmire, new website somehow worse than the old one / gets no traffic, etc.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-05-30T16:14:50.134Z · LW(p) · GW(p)
Thanks! Despite the lack of SMART goals, I still feel like this reply gave me a better sense of what your priorities are & how you'll be assessing success/failure.
One failure mode– which I'm sure is already on your radar– is something like: "MIRI ends up producing lots of high-quality stuff but no one really pays attention. Policymakers and national security people are very busy and often only read things that (a) directly relate to their work or (b) are sent to them by someone who they respect."
Another is something like: "MIRI ends up focusing too much on making arguments/points that are convincing to general audiences but fail to understand the cruxes/views of the People Who Matter." (A strawman version of this is something like "MIRI ends up spending a lot of time in the Bay and there's lots of pressure to engage a bunch with the cruxes/views of rationalists, libertarians, e/accs, and AGI company employees. Meanwhile, the kinds of conversations happening among natsec folks & policymakers look very different, and MIRI's materials end up being less relevant/useful to this target audience."
I'm extremely confident that these are already on your radar, but I figure it might be worth noting that these are two of the failure modes I'm most worried about. (I guess besides the general boring failure mode along the lines of "hiring is hard and doing anything is hard and maybe things just stay slow and when someone asks what good materials you guys have produced the answer is still 'we're working on it'.)
(Final note: A lot of my questions and thoughts have been critical, but I should note that I appreciate what you're doing & I'm looking forward to following MIRI's work in the space! :D)
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T16:20:05.965Z · LW(p) · GW(p)
Yup to all of that. :)
comment by jaan · 2024-06-03T06:49:53.367Z · LW(p) · GW(p)
thank you for continuing to stretch the overton window! note that, luckily, the “off-switch” is now inside the window (though just barely so, and i hear that big tech is actively - and very myopically - lobbying against on-chip governance). i just got back from a UN AIAB meeting and our interim report does include the sentence “Develop and collectively maintain an emergency response capacity, off-switches and other stabilization measures” (while rest of the report assumes that AI will not be a big deal any time soon).
comment by wassname · 2024-06-03T08:52:58.399Z · LW(p) · GW(p)
Have you considered emphasizing this part of your position:
"We want to shut down AGI research including governments, military, and spies in all countries".
I think this is an important point that is missed in current regulation, which focuses on slowing down only the private sector. It's hard to achieve because policymakers often favor their own institutions, but it's absolutely needed, so it needs to be said early and often. This will actually win you points with the many people who are cynical of the institutions, who are not just libertarians, but a growing portion of the public.
I don't think anyone is saying this, but it fits your honest and confronting communication strategy.
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-06-03T20:20:22.471Z · LW(p) · GW(p)
I am not sure which way you intended that sentence. Did you mean:
A. We want to shut down all AGI research everywhere by everyone, or
B. We want to shut down AGI research and we also want to shut down governments and militaries and spies
I assume you meant the first thing, but want to be sure!
We support A. Eliezer has been very clear about that in his tweets. In broader MIRI communications, it depends on how many words we have to express our ideas, but when we have room we spell out that idea.
I agree that current / proposed regulation is mostly not aimed at A.
↑ comment by wassname · 2024-06-06T04:19:45.152Z · LW(p) · GW(p)
Definitely A, and while it's clear MIRI means well, I'm suggesting a focus on preventing military and spy arms races in AI. Because it seems like a likely failure mode, which no one is focusing on. It seems like a place where a bunch of blunt people can expand the Overton window to everyone's advantage.
MIRI has used nuclear non-proliferation as an example (getting lots of pushback). But non-proliferation did not stop new countries from getting the bomb, it did certainly did not stop existing countries from scaling up their nuclear arsenals. Global de-escalation after the end of the Cold War is what caused that. For example, look at this graph it doesn't go down after the 1968 treaty, it goes down after the Cold War (>1985).
We would not want to see a similar situation with AI, where existing countries race to scale up their efforts and research.
This is in no way a criticism, MIRI is probably already doing the most here, and facing criticism for it. I'm just suggesting the idea.
comment by TsviBT · 2024-05-31T20:46:54.903Z · LW(p) · GW(p)
IDK if there's political support that would be helpful and that could be affected by people saying things to their representatives. But if so, then it would be helpful to have a short, clear, on-point letter that people can adapt to send to their representatives. Things I'd want to see in such a letter:
- AGI, if created, would destroy all or nearly all human value.
- We aren't remotely on track to solving the technical problems that would need to be solved in order to build AGI without destroying all or nearly all human value.
- Many researchers say they are trying to build AGI and/or doing research that materially contributes toward building AGI. None of those researchers has a plausible plan for making AGI that doesn't destroy all or nearly all human value.
- As your constituent, I don't want all or nearly all human value to be destroyed.
- Please start learning about this so that you can lend your political weight to proposals that would address existential risk from AGI.
- This is more important to me than all other risks about AI combined.
Or something.
comment by Orpheus · 2024-05-31T17:59:55.564Z · LW(p) · GW(p)
Here are some event ideas/goals that could support the strategy:
- Policy briefings and workshops for government officials and advisors
- Roundtable discussions with national security experts
- Private briefing sessions with policymakers and their staff
- Premiere of a (hypothetical) documentary/movie highlighting AI x-risks
- Series of public seminars in important cities
- Media tour with key MIRI representatives
- Series of webinars and live Q&A sessions with AI experts
- Shaping the international 2025 'AI Action Summit' in France
- Academic symposia and guest lectures on AI x-risk mitigation
- Workshops organized in collaboration with relevant AI Safety organizations
Note these are general ideas, not informed by the specifics of MIRI's capabilities and interests.
(Our organization, Horizon Events, and myself personally are interested in helping MIRI with event goals - feel free to reach out via email o@horizonomega.org.)
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-06-03T20:22:12.448Z · LW(p) · GW(p)
Thanks for the ideas!
comment by Meme Marine (meme-marine) · 2024-05-30T00:28:51.552Z · LW(p) · GW(p)
Why does MIRI believe that an "AI Pause" would contribute anything of substance to the goal of protecting the human race? It seems to me that an AI pause would:
- Drive capabilities research further underground, especially in military contexts
- Force safety researchers to operate on weaker models, which could hamper their ability to conduct effective research
- Create a hardware overhang which would significantly increase the chance of a sudden catastrophic jump in capability that we are not prepared to handle
- Create widespread backlash against the AI Safety community among interest groups that would like to see AI development continued
- Be politically contentious, creating further points for tension between nations that could spark real conflict; at worst, you are handing the reins to the future to foreign countries, especially ones that don't care about international agreements - which are the countries you would probably least want to be in control of AGI.
In any case, I think you are going to have an extremely difficult time in your messaging. I think this strategy will not succeed and will most likely, like most other AI safety efforts, actively harm your efforts.
Every movement thinks they just need people to "get it". Including, and especially, lunatics. If you behave like lunatics, people will treat you as such. This is especially true when there is a severe lack of evidence as to your conclusions. Classical AI Alignment theory does not apply to LLM-derived AI systems and I have not seen anything substantial to replace it. I find no compelling evidence to suggest even a 1% chance of x-risk from LLM-based systems. Anthropogenic climate change has mountains of evidence to support it, and yet a significant chunk of the population does not believe in it.
You are not telling people what they want to hear. Concerns around AI revolve around copyright infringement, job displacement, the shift of power between labor and capital, AI impersonation, data privacy, and just plain low-quality AI slop taking up space online and assaulting their eyeballs. The message every single news outlet has been publishing is: "AI is not AGI and it's not going to kill us all, but it might take your job in a few years" - that is, I think, the consensus opinion. Reframing some of your argument in these terms might make them a lot more palatable, at least to the people in the mainstream who already lean anti-AI. As it stands, even though the majority of Americans have a negative opinion on AI, they are very unlikely to support the kind of radical policies you propose, and lawmakers, who have an economic interest in the success of AI product companies, will be even less convinced.
I'm sorry if this takes on an insolent tone but surely you guys understand why everyone else plays the game, right? They're not doing it for fun, they're doing it because that's the best and only way to get anyone to agree with your political ideas. If it takes time, then you had better start right now. If a shortcut existed, everyone would take it. And then it would cease to be a shortcut. You have not found a trick to expedite the process, you have stumbled into a trap for fanatics. People will tune you out among the hundreds of other groups that also believe the world will end and that their radical actions are necessary to save it. Doomsday cults are a dime a dozen. Behaving like them will produce the same results as them: ridicule.
Replies from: Seth Herd, T3t, CronoDAS↑ comment by Seth Herd · 2024-05-30T03:42:29.036Z · LW(p) · GW(p)
There's a dramatic difference between this message and the standard fanatic message: a big chunk of it is both true, and intuitively so.
The idea that genuine smarter-than-humans-in-every-way AGI is dangerous is quite intuitive. How many people would say that, if we were visited by a more capable alien species, that would be totally safe for us?
The reason people don't intuitively see AI as dangerous is that they imagine it won't become fully agentic and genuinely outclass humans in all relevant ways. Convincing them otherwise is a complex argument, but continued progress will make that argument for us (unless it's all underground, which is a real risk as you say).
Now, that's not the part of their message that MIRI tends to emphasize. I think they had better, and I think they probably will.
That message actually benefits from not mixing it with any of the complex risks from sub-sapient tool AI that you mention. Doing what you suggest and using existing fears has dramatic downsides (although it still might be wise on a careful analysis - I haven't seen one that's convincing).
I agree with you that technical alignment of LLM-based AGI is quite achievable. I think we have plans for it that are underappreciated. Take a look at my publications, where I argue that technical alignment is probably quite achievable. I think you're overlooking some major danger points if you somehow get to a less than 1% risk.
- LLMs aren't the end of powerful AI, they're the start. Your use of "LLM-derived AI" indicates that you're not even thinking about the real AGI that will follow them. Even agents built out of of LLMs have novel alignment risks that the LLMs do not
- People do foolish things. For evidence, see history.
- Complex projects are hard to get right on the first try.
- Even if we solve technical intent alignment, we may very well kill ourselves in an escalating conflict powered by AGIs controlled by conflicting factions, terrorists, or idiots. Or combinations of those three.
Those last two are major components of why Eliezer and Nate are pessimistic. I wish it were a bigger part of their message. I think YK is quite wrong that technical alignment is very difficult, but I'm afraid he's right that obtaining a good outcome is going to be difficult.
Finally and separately: you appear to not understand that MIRI leadership thinks that AGI spells doom no matter who accomplishes it. They might be right or wrong, but that's what they think and they do have reasons. So handing the lead to bad actors isn't really a downside for them (it is to me, given my relative optimism, but this isn't my plan).
Replies from: meme-marine↑ comment by Meme Marine (meme-marine) · 2024-05-31T04:03:08.180Z · LW(p) · GW(p)
No message is intuitively obvious; the inferential distance between the AI safety community and the general public is wide, and even if many people do broadly dislike AI, they will tend to think that apocalyptic predictions of the future, especially ones that don't have as much hard evidence to back them as climate change (which is already very divisive!) belong in the same pile as the rest of them. I am sure many people will be convinced, especially if they were already predisposed to it, but such a radical message will alienate many potential supporters.
I think the suggestion that contact with non-human intelligence is inherently dangerous is not actually widely intuitive. A large portion of people across the world believe they regularly commune with non-human intelligence (God/s) which they consider benevolent. I also think this is a case of generalizing from fictional evidence - mentioning "aliens" conjures up stories like the War of the Worlds. So I think that, while this is definitely a valid concern, it will be far from a universally understood one.
I mainly think that using existing risks to convince people of their message would help because it would lower the inferential distance between them and their audience. Most people are not thinking about dangerous, superhuman AI, and will not until it's too late (potentially). Forming coalitions is a powerful tool in politics and I think throwing this out of the window is a mistake.
The reason I say LLM-derived AI is that I do think that to some extent, LLMs are actually a be-all-end-all. Not language models in particular, but the idea of using neural networks to model vast quantities of data, generating a model of the universe. That is what an LLM is and it has proven wildly successful. I agree that agents derived from them will not behave like current-day LLMs, but will be more like them than different. Major, classical misalignment risks would stem from something like a reinforcement learning optimizer.
I am aware of the argument of dangerous AI in the hands of ne'er do wells, but such people already exist and in many cases, are able to - with great effort - obtain means of harming vast amounts of people. Gwern Branwen covered this; there are a few terrorist vectors that would require relatively minuscule amounts of effort but that would result in a tremendous expected value of terror output. I think in part, being a madman hampers one's ability to rationally plan the greatest terror attack one's means could allow, and also that the efforts dedicated to suppressing such individuals vastly exceed the efforts of those trying to destroy the world. In practice, I think there would be many friendly AGI systems that would protect the earth from a minority of ones tasked to rogue purposes.
I also agree with your other points, but they are weak points compared to the rock-solid reasoning of misalignment theory. They apply to many other historical situations, and yet, we have ultimately survived; more people do sensible things than foolish things, and we do often get complex projects right the first time around as long as there is a theoretical underpinning to them that is well understood - I think proto-AGI is almost as well understood as it needs to be, and that Anthropic is something like 80% of the way to cracking the code.
I am afraid I did forget in my original post that MIRI would believe that the person who holds AGI is of no consequence. It simply struck me as so obvious I didn't think anyone could disagree with this.
In any case, I plan to write a longer post in collaboration with some friends who will help me edit it to not sound quite like the comment I left yesterday, in opposition of the PauseAI movement, which MIRI is a part of.
↑ comment by RobertM (T3t) · 2024-05-30T01:09:48.126Z · LW(p) · GW(p)
This comment doesn't seem to be responding to the contents of the post at all, nor does it seem to understand very basic elements of the relevant worldview it's trying to argue against (i.e. "which are the countries you would probably least want to be in control of AGI"; no, it doesn't matter which country ends up building an ASI, because the end result is the same).
It also tries to leverage arguments that depend on assumptions not shared by MIRI (such as that research on stronger models is likely to produce enough useful output to avert x-risk, or that x-risk is necessarily downstream of LLMs).
Replies from: meme-marine↑ comment by Meme Marine (meme-marine) · 2024-05-30T02:57:21.815Z · LW(p) · GW(p)
I am sorry for the tone I had to take, but I don't know how to be any clearer - when people start telling me they're going to "break the overton window" and bypass politics, this is nothing but crazy talk. This strategy will ruin any chances of success you may have had. I also question the efficacy of a Pause AI policy in the first place - and one argument against it is that some countries may defect, which could lead to worse outcomes in the long term.
comment by dr_s · 2024-06-03T09:10:28.353Z · LW(p) · GW(p)
We think audiences are numb to politics as usual. They know when they’re being manipulated. We have opted out of the political theater, the kayfabe, with all its posing and posturing. We are direct and blunt and honest, and we come across as exactly what we are.
This is IMO a great point, and true in general. I think "the meta" is sort of shifting and it's the guys who try too hard to come off as diplomatic who are often behind the curve. This has good and bad sides (sometimes it means that political extremism wins out over common sense simply because it's screechy and transgressive), but overall I think you got the pulse right on it.
comment by ShardPhoenix · 2024-05-30T03:28:42.697Z · LW(p) · GW(p)
What leads MIRI to believe that this policy of being very outspoken will work better than the expert-recommended policy of being careful what you say?
(Not saying it won't work, but this post doesn't seem to say why you think it will).
↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T15:32:01.191Z · LW(p) · GW(p)
We think that most people who see political speech know it to be political speech and automatically discount it. We hope that speaking in a different way will cut through these filters.
Replies from: Erich_Grunewald↑ comment by Erich_Grunewald · 2024-06-02T16:26:42.728Z · LW(p) · GW(p)
That's one reason why an outspoken method could be better. But it seems like you'd want some weighing of the pros and cons here? (Possible drawbacks of such messaging could include it being more likely to be ignored, or cause a backlash, or cause the issue to become polarized, etc.)
Like, presumably the experts who recommend being careful what you say also know that some people discount obviously political speech, but still recommend/practice being careful what you say. If so, that would suggest this one reason is not on its own enough to override the experts' opinion and practice.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2024-06-02T22:56:48.125Z · LW(p) · GW(p)
Could we talk about a specific expert you have in mind, who thinks this is a bad strategy in this particular case?
AI risk is a pretty weird case, in a number of ways: it's highly counter-intuitive, not particularly politically polarized / entrenched, seems to require unprecedentedly fast and aggressive action by multiple countries, is almost maximally high-stakes, etc. "Be careful what you say, try to look normal, and slowly accumulate political capital and connections in the hope of swaying policymakers long-term" isn't an unconditionally good strategy, it's a strategy adapted to a particular range of situations and goals. I'd be interested in actually hearing arguments for why this strategy is the best option here, given MIRI's world-model.
(Or, separately, you could argue against the world-model, if you disagree with us about how things are.)
Replies from: Erich_Grunewald↑ comment by Erich_Grunewald · 2024-06-05T09:37:37.097Z · LW(p) · GW(p)
I don't really have a settled view on this; I'm mostly just interested in hearing a more detailed version of MIRI's model. I also don't have a specific expert in mind, but I guess the type of person that Akash occasionally refers to -- someone who's been in DC for a while, focuses on AI, and has encouraged a careful/diplomatic communication strategy.
“Be careful what you say, try to look normal, and slowly accumulate political capital and connections in the hope of swaying policymakers long-term” isn’t an unconditionally good strategy, it’s a strategy adapted to a particular range of situations and goals.
I agree with this. I also think that being more outspoken is generally more virtuous in politics, though I also see drawbacks with it. Maybe I'd wished OP mentioned some of the possible drawbacks of the outspoken strategy and whether there are sensible ways to mitigate those, or just making clear that MIRI thinks they're outweighed by the advantages. (There's some discussion, e.g., the risk of being "discounted or uninvited in the short term", but this seems to be mostly drawn from the "ineffective" bucket, not from the "actively harmful" bucket.)
AI risk is a pretty weird case, in a number of ways: it’s highly counter-intuitive, not particularly politically polarized / entrenched, seems to require unprecedentedly fast and aggressive action by multiple countries, is almost maximally high-stakes, etc.
Yeah, I guess this is a difference in worldview between me and MIRI, where I have longer timelines, am less doomy, and am more bullish on forceful government intervention, causing me to think increased variance is probably generally bad.
That said, I'm curious why you think AI risk is highly counterintuitive (compared to, say, climate change) -- it seems the argument can be boiled down to a pretty simple, understandable (if reductive) core ("AI systems will likely be very powerful, perhaps more than humans, controlling them seems hard, and all that seems scary"), and it has indeed been transmitted like that successfully in the past, in films and other media.
I'm also not sure why it's relevant here that AI risk is relatively unpolarized -- if anything, that seems like it should make it more important not to cause further polarization (at least if highly visible moral issues being relatively unpolarized represent unstable equilibriums)?
comment by ryan_greenblatt · 2024-05-29T22:18:13.670Z · LW(p) · GW(p)
building misaligned smarter-than-human systems will kill everyone, including their children [...] if they come to understand this central truth.
I'd like to once again reiterate that the arguments for misaligned AIs killing literally all humans (if they succeed in takeover) are quite weak and probably literally all humans dying conditional on AI takeover is unlikely (<50% likely).
(To be clear, I think there is a substantial chance of at least 1 billion people dying and that AI takeover is very bad from a longtermist perspective.)
This is due to:
- The potential for the AI to be at least a tiny bit "kind" (same as humans probably wouldn't kill all aliens). [1]
- Decision theory/trade reasons
This is discussed in more detail here [LW(p) · GW(p)] and here [LW(p) · GW(p)]. (There is also some discussion here [LW(p) · GW(p)].)
(This content is copied from here [LW(p) · GW(p)] and there is some discussion there.)
Further, as far as I can tell, central thought leaders of MIRI (Eliezer, Nate Soares) don't actually believe that misaligned AI takeover will lead to the deaths of literally all humans:
Here Eliezer says [LW(p) · GW(p)]:
I sometimes mention the possibility of being stored and sold to aliens a billion years later, which seems to me to validly incorporate most all the hopes and fears and uncertainties that should properly be involved, without getting into any weirdness that I don't expect Earthlings to think about validly.
Here Soares notes [LW(p) · GW(p)]:
I'm somewhat persuaded by the claim that failing to mention even the possibility of having your brainstate stored, and then run-and-warped by an AI or aliens or whatever later, or run in an alien zoo later, is potentially misleading.
I think it doesn't cost that much more to just keep humans physically alive [LW(p) · GW(p)], so if you're imagining scanning for uploads, just keeping people alive is also plausible IMO. Perhaps this is an important crux?!?
Insofar as MIRI is planning on focusing on straightforwardly saying what they think as a comms strategy, it seems important to resolve this issue.
I'd be personally be happy with either:
- Change the message to something like "building misaligned smarter-than-human systems will kill high fractions of humanity, including their children" (insofar as MIRI believes this)
- More seriously defend the claims that AIs will only retain a subset brain scans for aliens (rather than keeping humans alive and happy or quickly reviving all humans into a good-for-each-human situation) and where reasonable include "AIs might retain brain scans that are later revived" (E.g. no need to include this in central messaging, I think it is reasonable (from an onion honesty perspective [LW · GW]) to describe AIs as "killing all of us" if they physically kill all humans and then brain scan only a subset and sell these brain scans.)
(Edit: I clarify some of where I'm coming from here [LW(p) · GW(p)].)
This includes the potential for the AI to generally have preferences that are morally valueable from a typical human perspective. ↩︎
↑ comment by Seth Herd · 2024-05-30T03:18:03.691Z · LW(p) · GW(p)
The more complex messges sounds like a great way to make the public communication more complex and offputting.
The difference between killing everyone and killing almost everyone while keeping a few alive for arcane purposes does not matter to most people, nor should it.
I agree that the arguments for misaligned AGI killing absolutely everyone aren't solid, but the arguments against that seem at least as shaky. So rounding it to "might quite possibly kill everyone" seems fair and succinct.
From the other thread where this comment originated: the argument that AGI won't kill everyone because people wouldn't kill everyone seems very bad, even when applied to human-imitating LLM-based AGI. People are nice because evolution meticulously made us nice. And even humans have killed an awful lot of people, with no sign they'd stop before killing everyone if it seemed useful for their goals.
Replies from: ryan_greenblatt, ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T03:41:50.213Z · LW(p) · GW(p)
Why not "AIs might violently takeover the world"?
Seems accurate to the concern while also avoiding any issues here.
Replies from: gretta-duleba, Seth Herd↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T15:21:47.419Z · LW(p) · GW(p)
That phrase sounds like the Terminator movies to me; it sounds like plucky humans could still band together to overthrow their robot overlords. I want to convey a total loss of control.
In documents where we have more room to unpack concepts I can imagine getting into some of the more exotic scenarios like aliens buying brain scans, but mostly I don't expect our audiences to find that scenario reassuring in any way, and going into any detail about it doesn't feel like a useful way to spend weirdness points.
Some of the other things you suggest, like future systems keeping humans physically alive, do not seem plausible to me. Whatever they're trying to do, there's almost certainly a better way to do it than by keeping Matrix-like human body farms running.
Replies from: Zack_M_Davis, RobbBB, ryan_greenblatt, ryan_greenblatt, davekasten↑ comment by Zack_M_Davis · 2024-05-30T23:25:34.490Z · LW(p) · GW(p)
going into any detail about it doesn't feel like a useful way to spend weirdness points.
That may be a reasonable consequentialist decision given your goals, but it's in tension with your claim in the post to be disregarding the advice of people telling you to "hoard status and credibility points, and [not] spend any on being weird."
Whatever they're trying to do, there's almost certainly a better way to do it than by keeping Matrix-like human body farms running.
You've completely ignored the arguments from Paul Christiano that Ryan linked to at the top of the thread. (In case you missed it: 1 [LW(p) · GW(p)] 2 [LW(p) · GW(p)].)
The claim under consideration is not that "keeping Matrix-like human body farms running" arises as an instrumental subgoal of "[w]hatever [AIs are] trying to do." (If you didn't have time to read the linked arguments, you could have just said that instead of inventing an obvious strawman.)
Rather, the claim is that it's plausible that the AI we build (or some agency that has decision-theoretic bargaining power with it) cares about humans enough to spend some tiny fraction of the cosmic endowment on our welfare. (Compare to how humans care enough about nature preservation and animal welfare to spend some resources on it, even though it's a tiny fraction of what our civilization is doing.)
Maybe you think that's implausible, but if so, there should be a counterargument explaining why Christiano is wrong. As Ryan notes, Yudkowsky seems to believe that some scenarios in which an agency with bargaining power cares about humans are plausible, describing one example of such as [LW(p) · GW(p)] "validly incorporat[ing] most all the hopes and fears and uncertainties that should properly be involved, without getting into any weirdness that I don't expect Earthlings to think about validly." I regard this statement as undermining your claim in the post that MIRI's "reputation as straight shooters [...] remains intact." Withholding information because you don't trust your audience to reason validly (!!) is not at all the behavior of a "straight shooter".
Replies from: Benito, ryan_greenblatt↑ comment by Ben Pace (Benito) · 2024-05-31T06:10:35.458Z · LW(p) · GW(p)
I think it makes sense to state the more direct threat-model of literal extinction; though I am also a little confused by the citing of weirdness points… I would’ve said that it makes the whole conversation more complex in a way that (I believe) everyone would reliably end up thinking was not a productive use of time.
(Expanding on this a little: I think that literal extinction is a likely default outcome, and most people who are newly coming to this topic would want to know that this is even in the hypothesis-space and find that to be key information. I think if I said “also maybe they later simulate us in weird configurations like pets for a day every billion years while experiencing insane things” they would not respond “ah, never mind then, this subject is no longer a very big issue”, they would be more like “I would’ve preferred that you had factored this element out of our discussion so far, we spent a lot of time on it yet it still seems to me like the extinction event being on the table is the primary thing that I want to debate”.)
↑ comment by ryan_greenblatt · 2024-05-30T23:45:41.898Z · LW(p) · GW(p)
Withholding information because you don't trust your audience to reason validly (!!) is not at all the behavior of a "straight shooter".
Hmm, I'm not sure I exactly buy this. I think you should probably follow something like onion honesty [LW · GW] which can involve intentionally simplifying your message to something you expect will give the audience more true views. I think you should lean on the side of stating things, but still, sometimes stating a thing which is true can be clearly distracting and confusing and thus you shouldn't.
Replies from: Zack_M_Davis, Raemon↑ comment by Zack_M_Davis · 2024-05-31T02:21:57.732Z · LW(p) · GW(p)
Passing the onion test is better than not passing it, but I think the relevant standard is having intent to inform. There's a difference between trying to share relevant information in the hopes that the audience will integrate it with their own knowledge and use it to make better decisions, and selectively sharing information in the hopes of persuading the audience to make the decision you want them to make.
An evidence-filtering [LW · GW] clever arguer [LW · GW] can pass the onion test (by not omitting information that the audience would be surprised to learn was omitted) and pass the test of not technically lying [LW · GW] (by not making false statements) while failing to make a rational argument [LW · GW] in which the stated reasons are the real reasons.
↑ comment by Rob Bensinger (RobbBB) · 2024-06-02T02:32:03.597Z · LW(p) · GW(p)
Some of the other things you suggest, like future systems keeping humans physically alive, do not seem plausible to me.
I agree with Gretta here, and I think this is a crux. If MIRI folks thought it were likely that AI will leave a few humans biologically alive (as opposed to information-theoretically revivable), I don't think we'd be comfortable saying "AI is going to kill everyone". (I encourage other MIRI folks to chime in if they disagree with me about the counterfactual.)
I also personally have maybe half my probability mass on "the AI just doesn't store any human brain-states long-term", and I have less than 1% probability on "conditional on the AI storing human brain-states for future trade, the AI does in fact encounter aliens that want to trade and this trade results in a flourishing human civilization".
↑ comment by ryan_greenblatt · 2024-05-30T18:27:42.004Z · LW(p) · GW(p)
That phrase sounds like the Terminator movies to me; it sounds like plucky humans could still band together to overthrow their robot overlords. I want to convey a total loss of control.
Yeah, seems like a reasonable concern.
FWIW, I also do think that it is reasonably likely that we'll see conflict between human factions and AI factions (likely with humans allies) in which the human factions could very plausibly win. So, personally, I don't think that "immediate total loss of control" is what people should typically be imagining.
↑ comment by ryan_greenblatt · 2024-05-30T17:55:39.234Z · LW(p) · GW(p)
Some of the other things you suggest, like future systems keeping humans physically alive, do not seem plausible to me. Whatever they're trying to do, there's almost certainly a better way to do it than by keeping Matrix-like human body farms running.
Insofar as AIs are doing things because they are what existing humans want (within some tiny cost budget), then I expect that you should imagine that what actually happens is what humans want (rather than e.g. what the AI thinks they "should want") insofar as what humans want is cheap.
See also here [LW(p) · GW(p)] which makes a similar argument in response to a similar point.
So, if humans don't end up physically alive but do end up as uploads/body farms/etc one of a few things must be true:
- Humans didn't actually want to be physically alive and instead wanted to be uploads. In this case, it is very misleading to say "the AI will kill everyone (and sure there might be uploads, but you don't want to be an upload right?)" because we're conditioning on people deciding to become uploads!
- It was too expensive to keep people physically alive rather than uploads. I think this is possible but somewhat implausible: the main reasons for cost here apply to uploads as much as to keeping humans physically alive. In particular, death due to conflict or mass slaughter in cases where conflict was the AI's best option to increase the probability of long run control.
↑ comment by Tao Lin (tao-lin) · 2024-05-31T03:06:34.359Z · LW(p) · GW(p)
I don't think slaughtering billions of people would be very useful. As a reference point, wars between countries almost never result in slaughtering that large a fraction of people
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-31T04:40:49.145Z · LW(p) · GW(p)
Unfortunately, if the AI really barely cares (e.g. <1/billion caring), it might only need to be barely useful.
I agree it is unlikely to be very useful.
↑ comment by davekasten · 2024-05-30T21:42:12.607Z · LW(p) · GW(p)
I would like to +1 the "I don't expect our audiences to find that scenario reassuring in any way" -- I would also add that the average policymaker I've ever met wouldn't find a lack of including the exotic scenarios to be in any way inaccurate or deceitful, unless you were way in the weeds for a multi-hour convo and-or they asked you in detail for "well, are there any weird edge cases where we make it through".
↑ comment by ryan_greenblatt · 2024-05-31T05:11:07.705Z · LW(p) · GW(p)
The difference between killing everyone and killing almost everyone while keeping a few alive for arcane purposes does not matter to most people, nor should it.
I basically agree with this as stated, but think these arguments also imply that it is reasonably likely that the vast majority of people will survive misaligned AI takeover (perhaps 50% likely).
I also don't think this is very well described as arcane purposes:
- Kindness is pretty normal.
- Decision theory motivations is actually also pretty normal from some perspective: it's just the generalization of relatively normal "if you wouldn't have screwed me over and it's cheap for me, I won't screw you over". (Of course, people typically don't motivate this sort of thing in terms of decision theory so there is a bit of a midwit meme here.)
↑ comment by Seth Herd · 2024-05-31T18:38:27.300Z · LW(p) · GW(p)
You're right. I didn't mean to say that kindness is arcane. I was referring to acausal trade or other strange reasons to keep some humans around for possible future use.
Kindness is normal in our world, but I wouldn't assume it will exist in every or even most situations with intelligent beings. Humans are instinctively kind (except for sociopathic and sadistic people), because that is good game theory for our situation: interactions with peers, in which collaboration/teamwork is useful.
A being capable of real recursive self-improvement, let alone duplication and creation of subordinate minds is not in that situation. They may temporarily be dealing with peers, but they might reasonably expect to have no need of collaborators in the near future. Thus, kindness isn't rational for that type of being.
The exception would be if they could make a firm commitment to kindness while they do have peers and need collaborators. They might have kindness merely as an instrumental goal, in which case it would be abandoned as soon as it was no longer useful.
Or they might display kindness more instinctively, as a tendency in their thought or behavior. They might even have it engineered as an innate goal, as Steve hopes to engineer. In those last two cases, I think it's possible that reflexive stability would keep that kindness in place as the AGI continued to grow, but I wouldn't bet on it unless kindness was their central goal. If it was merely a tendency and not an explicit and therefore self-endorsed goal, I'd expect it to be dropped like the bad habit it effectively is. If it was an innate goal but not the strongest one, I don't know but wouldn't bet on it being long-term reflexively stable under deliberate self-modification.
(As far as I know, nobody has tried hard to work through the logic of reflexive stability of multiple goals. I tried, and gave it up as too vague and less urgent than other alignment questions. My tentative answer was maybe multiple goals would be reflectively stable; it depends on the exact structure of the decision-making process in that AGI/mind).
↑ comment by ryan_greenblatt · 2024-05-30T18:24:58.229Z · LW(p) · GW(p)
Here's another way to frame why this matters.
When you make a claim like "misaligned AIs kill literally everyone", then reasonable people will be like "but will they?" and you should be a in a position where you can defend this claim. But actually, MIRI doesn't really want to defend this claim against the best objections (or at least they haven't seriously done so yet AFAICT).
Further, the more MIRI does this sort of move, the more that reasonable potential allies will have to distance themselves.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2024-05-30T19:38:49.623Z · LW(p) · GW(p)
When you make a claim like "misaligned AIs kill literally everyone", then reasonable people will be like "but will they?" and you should be a in a position where you can defend this claim.
I think most reasonable people will round off "some humans may be kept as brain scans that may have arbitrary cruelties done to them" to be equivalent to "everyone will be killed (or worse)" and not care about this particular point, seeing it as nitpicking that would not make the scenario any less horrible even if it was true.
Replies from: habryka4, RobbBB↑ comment by habryka (habryka4) · 2024-05-30T21:03:05.902Z · LW(p) · GW(p)
I disagree. I think it matters a good amount. Like if the risk scenario is indeed "humans will probably get a solar system or two because it's cheap from the perspective of the AI". I also think there is a risk of AI torturing the uploads it has, and I agree that if that is the reason why humans are still alive then I would feel comfortable bracketing it, but I think Ryan is arguing more that something like "humans will get a solar system or two and basically get to have decent lives".
Replies from: ryan_greenblatt, Benito↑ comment by ryan_greenblatt · 2024-05-30T22:50:57.932Z · LW(p) · GW(p)
Ryan is arguing more that something like "humans will get a solar system or two and basically get to have decent lives".
Yep, this is an accurate description, but it is worth emphasizing that I think that horrible violent conflict and other bad outcomes for currently alive humans are reasonably likely.
↑ comment by Ben Pace (Benito) · 2024-05-30T21:28:24.275Z · LW(p) · GW(p)
IMO this is an utter loss scenario, to be clear.
Replies from: habryka4, akash-wasil↑ comment by habryka (habryka4) · 2024-05-30T21:39:59.092Z · LW(p) · GW(p)
I am not that confident about this. Or like, I don't know, I do notice my psychological relationship to "all the stars explode" and "earth explodes" is very different, and I am not good enough at morality to be confident about dismissing that difference.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2024-05-30T22:48:12.407Z · LW(p) · GW(p)
There's definitely some difference, but I still think that the mathematical argument is just pretty strong, and losing a multiple of of your resources for hosting life and fun and goodness seems to me extremely close to "losing everything".
↑ comment by Orpheus16 (akash-wasil) · 2024-05-30T21:35:00.502Z · LW(p) · GW(p)
@habryka [LW · GW] I think you're making a claim about whether or not the difference matters (IMO it does) but I perceived @Kaj_Sotala [LW · GW] to be making a claim about whether "an average reasonably smart person out in society" would see the difference as meaningful (IMO they would not).
(My guess is you interpreted "reasonable people" to mean like "people who are really into reasoning about the world and trying to figure out the truth" and Kaj interpreted reasonable people to mean like "an average person." Kaj should feel free to correct me if I'm wrong.)
Replies from: Linch↑ comment by Linch · 2024-05-30T23:03:27.300Z · LW(p) · GW(p)
The details matter here! Sometimes when (MIRI?) people say "unaligned AIs might be a bit nice and may not literally kill everyone" the modal story in their heads is something like some brain states of humans are saved in a hard drive somewhere for trade with more competent aliens. And sometimes when other people [1]say "unaligned humans might be a bit nice and may not literally kill everyone" the modal story in their heads is that some X% of humanity may or may not die in a violent coup, but the remaining humans get to live their normal lives on Earth (or even a solar system or two), with some AI survelliance but our subjective quality of life might not even be much worse (and might actually be better).
From a longtermist perspective, or a "dignity of human civilization" perspective, maybe the stories are pretty similar. But I expect "the average person" to be much more alarmed by the first story than the second, and not necessarily for bad reasons.
- ^
I don't want to speak for Ryan or Paul, but at least tentatively this is my position: I basically think the difference from a resource management perspective of whether to keep humans around physically vs copies of them saved is ~0 when you have the cosmic endowment to play with, so small idiosyncratic preferences that's significant enough to want to save human brain states should also be enough to be okay with keeping humans physically around; especially if humans strongly express a preference for the latter happening (which I think they do).
↑ comment by Rob Bensinger (RobbBB) · 2024-06-02T02:34:18.004Z · LW(p) · GW(p)
Note that "everyone will be killed (or worse)" is a different claim from "everyone will be killed"! (And see Oliver's point that Ryan isn't talking about mistreated brain scans.)
↑ comment by Jozdien · 2024-05-30T13:13:02.509Z · LW(p) · GW(p)
Further, as far as I can tell, central thought leaders of MIRI (Eliezer, Nate Soares) don't actually believe that misaligned AI takeover will lead to the deaths of literally all humans:
This is confusing to me; those quotes are compatible with Eliezer and Nate believing that it's very likely that misaligned AI takeover leads to the deaths of literally all humans.
Perhaps you're making some point about how if they think it's at all plausible that it doesn't lead to everyone dying, they shouldn't say "building misaligned smarter-than-human systems will kill everyone". But that doesn't seem quite right to me: if someone believed event X will happen with 99.99% probability and they wanted to be succinct, I don't think it's very unreasonable to say "X will happen" instead of "X is very likely to happen" (as long as when it comes up at all, they're honest with their estimates).
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T17:04:56.970Z · LW(p) · GW(p)
I agree these quotes are compatible with them thinking that the deaths of literally all humans are likely conditional on misaligned AI takeover.
I also agree that if they think that it is >75% likely that AI will kill literally everyone, then it seems like a reasonable and honest to say "misaligned AI takeover will kill literally everyone".
I also think it seems fine to describe the situation as "killing literally everyone" even if the AI preserve a subset of humans as brain scans and sell those scans to aliens. (Though probably this should be caveated in various places.
But, I think that they don't actually put >75% probability on AI killing literally everyone and these quotes are some (though not sufficient) evidence for this. Or more minimally, they don't seem to have made a case for the AI killing literally everyone which addresses the decision theory counterargument effectively. (I do think Soares and Eliezer have argued for AIs not caring at all aside from decision theory grounds, though I'm also skeptical about this.)
Replies from: Jozdien↑ comment by Jozdien · 2024-05-30T17:18:58.385Z · LW(p) · GW(p)
they don't seem to have made a case for the AI killing literally everyone which addresses the decision theory counterargument effectively.
I think that's the crux here. I don't think the decision theory counterargument alone would move me from 99% to 75% - there are quite a few other reasons my probability is lower than that, but not purely on the merits of the argument in focus here. I would be surprised if that weren't the case for many others as well, and very surprised if they didn't put >75% probably on AI killing literally everyone.
I guess my position comes down to: There are many places where I and presumably you disagree with Nate and Eliezer's view and think their credences are quite different from ours, and I'm confused by the framing of this particular one as something like "this seems like a piece missing from your comms strategy". Unless you have better reasons than I for thinking they don't put >75% probability on this - which is definitely plausible and may have happened in IRL conversations I wasn't a part of, in which case I'm wrong.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T17:46:35.078Z · LW(p) · GW(p)
I'm confused by the framing of this particular one as something like "this seems like a piece missing from your comms strategy". Unless you have better reasons than I for thinking they don't put >75% probability on this - which is definitely plausible and may have happened in IRL conversations I wasn't a part of, in which case I'm wrong.
Based partially on my in person interactions with Nate and partially on some amalgamated sense from Nate and Eliezer's comments on the topic, I don't think they seem very commited to the view "the AI will kill literally everyone".
Beyond this, I think Nate's posts on the topic (here [LW · GW], here [LW · GW], and here [LW · GW]) don't seriously engage with the core arguments (listed in my comment) while simultaneously making a bunch of unimportant arguments that totally bury the lede.[1] See also my review of one of these posts here [LW(p) · GW(p)] and Paul's comment here [LW(p) · GW(p)] making basically the same point.
I think it seems unfortunate to:
- Make X part of your core comms messaging. (Because X is very linguistically nice.)
- Make a bunch of posts hypothetically argueing for conclusion X while not really engaging with the best counterarguments and while making a bunch of points that bury the lede.
- When these counterarguments are raised, note that you haven't really thought much about the topic and that this isn't much of a crux for you because a high fraction of your motivation is longtermist (see here [LW(p) · GW(p)]).
Relevant quote from Nate:
I am not trying to argue with high confidence that humanity doesn't get a small future on a spare asteroid-turned-computer or an alien zoo or maybe even star if we're lucky, and acknowledge again that I haven't much tried to think about the specifics of whether the spare asteroid or the alien zoo or distant simulations or oblivion is more likely, because it doesn't much matter relative to the issue of securing the cosmic endowment in the name of Fun.
To be clear, I think AIs might kill huge numbers of people. Also, whether misaligned AI takeover kills everyone with >90% probability or kills billions with 50% probability doesn't effect the bottom line for stopping takeover much from most people's perspective! I just think it would be good to fix the messaging here to something more solid.
(I have a variety of reasons for thinking this sort of falsehood is problematic which I could get into as needed.)
Edit: note that some of these posts make correct points about unrelated and important questions (e.g. making IMO correct arguments that you very likely can't bamboozle a high fraction of resources out of an AI using decision theory), I'm just claiming that with respect to the question of "will the AI kill all humans" these posts fail to engage with the strongest arguments and bury the lede. ↩︎
↑ comment by Rob Bensinger (RobbBB) · 2024-06-02T03:12:26.509Z · LW(p) · GW(p)
Two things:
- For myself, I would not feel comfortable using language as confident-sounding as "on the default trajectory, AI is going to kill everyone" if I assigned (e.g.) 10% probability to "humanity [gets] a small future on a spare asteroid-turned-computer or an alien zoo or maybe even star". I just think that scenario's way, way less likely than that.
- I'd be surprised if Nate assigns 10+% probability to scenarios like that, but he can speak for himself. 🤷♂️
- I think some people at MIRI have significantly lower p(doom)? And I don't expect those people to use language like "on the default trajectory, AI is going to kill everyone".
- I agree with you that there's something weird about making lots of human-extinction-focused arguments when the thing we care more about is "does the cosmic endowment get turned into paperclips"? I do care about both of those things, an enormous amount; and I plan to talk about both of those things to some degree in public communications, rather than treating it as some kind of poorly-kept secret that MIRI folks care about whether flourishing interstellar civilizations get a chance to exist down the line. But I have this whole topic mentally flagged as a thing to be thoughtful and careful about, because it at least seems like an area that contains risk factors for future deceptive comms. E.g., if we update later to expecting the cosmic endowment to be wasted but all humans not dying, I would want us to adjust our messaging even if that means sacrificing some punchiness in our policy outreach.
- Currently, however, I think the particular scenario "AI keeps a few flourishing humans around forever" is incredibly unlikely, and I don't think Eliezer, Nate, etc. would say things like "this has a double-digit probability of happening in real life"? And, to be honest, the idea of myself and my family and friends and every other human being all dying in the near future really fucks me up and does not seem in any sense OK, even if (with my philosopher-hat on) I think this isn't as big of a deal as "the cosmic endowment gets wasted".
- So I don't currently feel bad about emphasizing a true prediction ("extremely likely that literally all humans literally nonconsensually die by violent means"), even though the philosophy-hat version of me thinks that the separate true prediction "extremely likely 99+% of the potential value of the long-term future is lost" is more morally important than that. Though I do feel obliged to semi-regularly mention the whole "cosmic endowment" thing in my public communication too, even if it doesn't make it into various versions of my general-audience 60-second AI risk elevator pitch.
↑ comment by ryan_greenblatt · 2024-06-02T03:41:16.909Z · LW(p) · GW(p)
Thanks, this is clarifying from my perspective.
My remaining uncertainty is why you think AIs are so unlikely to keep humans around and treat them reasonably well (e.g. let them live out full lives).
From my perspective the argument that it is plausible that humans are treated well [even if misaligned AIs end up taking over the world and gaining absolute power] goes something like this:
- If it only cost >1/million of overall resources to keep a reasonable fraction of humans alive and happy, it's reasonably likely that misaligned AIs with full control would keep humans alive and happy due to either:
- Acausal trade/decision theory
- The AI terminally caring at least a bit about being nice to humans (perhaps because it cares a bit about respecting existing nearby agents or perhaps because it has at least a bit of human like values).
- It is pretty likely that it costs <1/million of overall resources (from the AI's perspective) to keep a reaonable fraction of humans alive and happy. Humans are extremely keep to keep around asymptotically and I think it can be pretty cheap even initially, especially if you're a very smart AI.
(See links in my prior comment for more discussion.)
(I also think the argument goes through for 1/billion, but I thought I would focus on the higher value for now.)
Where do you disagree with this argument?
↑ comment by habryka (habryka4) · 2024-05-29T23:23:32.682Z · LW(p) · GW(p)
FWIW I still stand behind the arguments that I made in that old thread with Paul. I do think the game-theoretical considerations for AI maybe allowing some humans to survive are stronger, but they also feel loopy and like they depend on how good of a job we do on alignment, so I usually like to bracket them in conversations like this (though I agree it's relevant for the prediction of whether AI will kill literally everyone).
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T18:00:18.295Z · LW(p) · GW(p)
[minor]
they depend on how good of a job we do on alignment
Worth noting that they might only depend to some extent as mediated by the correlation between our success and alien's success.
High competent aliens which care a bunch about killing a bunch of existing beings seems pretty plausible to me.
↑ comment by Raemon · 2024-06-30T01:39:08.045Z · LW(p) · GW(p)
(To be clear, I think there is a substantial chance of at least 1 billion people dying and that AI takeover is very bad from a longtermist perspective.)
Is there a writeup somewhere of how we're likely to get "around a billion people die" that isn't extinction, or close to it? Something about this phrasing feels weird/suspicious to me.
Like I have a few different stories for everyone dying (some sooner, or later).
I have some stories where like "almost 8 billion people" die and the AI scans the remainder.
I have some stories where the AI doesn't really succeed and maybe kills millions of people, in what is more like "a major industrial accident" than "a powerful superintelligence enacting its goals".
Technically "substantial chance of at least 1 billion people dying" can imply the middle option there, but it sounds like you mean the central example to be closer to a billion than 7.9 billion or whatever. That feels like a narrow target and I don't really know what you have in mind.
Replies from: Raemon, ryan_greenblatt↑ comment by Raemon · 2024-06-30T17:15:35.539Z · LW(p) · GW(p)
Thinking a bit more, scenarios that seem at least kinda plausible:
- "misuse" where someone is just actively trying to use AI to commit genocide or similar. Or, we get into an humans+AI vs human+AI war.
- the AI economy takes off, it has lots of extreme environmental impact, and it's sort of aligned but we're not very good at regulating it fast enough, but, we get it under control after a billion death.
↑ comment by ryan_greenblatt · 2024-06-30T18:05:55.199Z · LW(p) · GW(p)
Some more:
- The AI kills a huge number of people with a bioweapon to destablize the world and relatively advantage its position.
- Massive world war/nuclear war. This could kill 100s of millions easily. 1 billion is probably a bit on the higher end of what you'd expect.
- The AI has control of some nations, but thinks that some subset of humans over which it has control pose a net risk such that mass slaughter is a good option.
- AIs would prefer to keep humans alive, but there are multiple misaligned AI factions racing and this causes extreme environmental damage.
↑ comment by ryan_greenblatt · 2024-06-30T18:07:35.978Z · LW(p) · GW(p)
Technically "substantial chance of at least 1 billion people dying" can imply the middle option there, but it sounds like you mean the central example to be closer to a billion than 7.9 billion or whatever. That feels like a narrow target and I don't really know what you have in mind.
I think "crazy large scale conflict (with WMDs)" or "mass slaughter to marginally increase odds of retaining control" or "extreme environmental issues" are all pretty central in what I'm imagining.
I think the number of deaths for these is maybe log normally distributed around 1 billion or so. That said, I'm low confidence.
(For reference, if the same fraction of people died as in WW2, it would be around 300 million. So, my view is similar to "substantial chance of a catastrophe which is a decent amount worse than WW2".)
↑ comment by Tenoke · 2024-05-30T11:21:46.089Z · LW(p) · GW(p)
unlikely (<50% likely).
That's a bizarre bar to me! 50%!? I'd be worried if it was 5%.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T17:02:05.307Z · LW(p) · GW(p)
I'm not arguing that you shouldn't be worried. I'm worried and I work on reducing AI risk as my full time job. I'm just arguing that it doesn't seem like true and honest messaging. (In the absence of various interventions I proposed in the bottom of my comment.)
Replies from: Tenoke↑ comment by Tenoke · 2024-05-30T18:00:47.038Z · LW(p) · GW(p)
Okay, then what are your actual probabilities? I'm guessing it's not sub-20% otherwise you wouldnt just say "<50%", because for me preventing a say 10% chance of extinction is much more important than even a 99% chance of 2B people dying. And your comment was specifically dismissing focus on full extinction due to the <50% chance.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T18:09:32.655Z · LW(p) · GW(p)
My current view is that conditional on ending up with full misaligned AI control:
- 20% extinction
- 50% chance >1 billion humans die or suffer outcome at least as bad as death.
for me preventing a say 10% chance of extinction is much more important than even a 99% chance of 2B people dying
I don't see why this would be true:
- From a longtermist perspective, we lose control over the lightcone either way (we're conditioning on full misaligned AI control).
- From a perspective where you just care about currently alive beings on planet earth, I don't see why extinction is that much worse.
- From a perspective in which you just want some being to be alive somewhere, I think that expansive notions of the universe/multiverse virtually guarantee this (but perhaps you dismiss this for some reason).
Also, to be clear, perspectives 2 and 3 don't seem very reasonable to me as terminal philosophical views (rather than e.g. heuristics) as they priviledge time and locations in space in a pretty specific way.
Replies from: Tenoke↑ comment by Tenoke · 2024-05-30T18:28:09.699Z · LW(p) · GW(p)
I have a preference for minds as close to mine continuing existence assuming their lives are worth living. If it's misaligned enough that the remaining humans don't have good lives, then yes it doesn't matter but I'd just lead with that rather than just the deaths.
And if they do have lives worth living and don't end up being the last humans, then that leaves us with a lot more positive-human-lived-seconds in the 2B death case.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T18:52:09.903Z · LW(p) · GW(p)
This view as stated seems very likely to be satisfied by e.g. everett branches. (See (3) on my above list.)
Replies from: Tenoke↑ comment by Tenoke · 2024-05-30T19:00:34.340Z · LW(p) · GW(p)
Sure, but 1. I only put 80% or so on MWI/MUH etc. and 2. I'm talking about optimizing for more positive-human-lived-seconds, not for just a binary 'I want some humans to keep living' .
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T19:03:30.623Z · LW(p) · GW(p)
I'm talking about optimizing for more positive-human-lived-seconds, not for just a binary 'I want some humans to keep living' .
Then why aren't you mostly dominated by the possibility of >10^50 positive-human-lived-seconds via human control of the light cone?
Maybe some sort of diminishing returns?
Replies from: Tenoke↑ comment by peterbarnett · 2024-05-30T17:26:12.053Z · LW(p) · GW(p)
I really want to be able to simply convey that I am worried about outcomes which are similarly bad to "AIs kill everyone". I put less than 50% that conditional on takeover, the AI's leave humans alive because of something like "kindness". I do think the decision theoretic reasons are maybe stronger, but I also don't think that is the kind of thing one can convey to the general public.
I think it might be good to have another way of describing the bad outcomes I am worried about.
I like your suggestion of "AIs kill high fractions of humanity, including their children", although it's a bit clunky. Some other options, but I'm still not super confident are better:
- AIs totally disempower humanity (I'm worried people will be like "Oh, but aren't we currently disempowered by capitalism/society/etc")
- Overthrow the US government (maybe good for NatSec stuff, but doesn't convey the full extent)
↑ comment by Orpheus16 (akash-wasil) · 2024-05-30T21:30:03.138Z · LW(p) · GW(p)
My two cents RE particular phrasing:
When talking to US policymakers, I don't think there's a big difference between "causes a national security crisis" and "kills literally everyone." Worth noting that even though many in the AIS community see a big difference between "99% of people die but civilization restarts" vs. "100% of people die", IMO this distinction does not matter to most policymakers (or at least matters way less to them).
Of course, in addition to conveying "this is a big deal" you need to convey the underlying threat model. There are lots of ways to interpret "AI causes a national security emergency" (e.g., China, military conflict). "Kills literally everyone" probably leads people to envision a narrower set of worlds.
But IMO even "kills literally everybody" doesn't really convey the underlying misalignment/AI takeover threat model.
So my current recommendation (weakly held) is probably to go with "causes a national security emergency" or "overthrows the US government" and then accept that you have to do some extra work to actually get them to understand the "AGI--> AI takeover--> Lots of people die and we lose control" model.
↑ comment by mako yass (MakoYass) · 2024-06-01T23:53:48.453Z · LW(p) · GW(p)
Agreed but initially downvoted due to being obviously unproductive, but then upvoted for being an exquisite proof by absurdity about what's productive: This is the first time I have seen clearly how good communication must forbid some amount of nuance.
The insight: You have a limited amount of time to communicate arguments and models; methods for reproducing some of your beliefs. With most people, you will never have enough time to transmit our entire technoeschatology or xenoeconomics stuff. It is useless to make claims about it, as the recipient has no way of checking them for errors or deceptions. You can only communicate approximations and submodules. No one will ever see the whole truth. (You do not see the whole truth. Your organization, even just within itself, will never agree about the whole truth.)
Replies from: ryan_greenblatt, CronoDAS↑ comment by ryan_greenblatt · 2024-06-02T02:08:38.878Z · LW(p) · GW(p)
upvoted for being an exquisite proof by absurdity about what's productive
I don't think you should generally upvote things on the basis of indirectly explaining things via being unproductive lol.
Replies from: MakoYass↑ comment by mako yass (MakoYass) · 2024-06-02T04:23:32.352Z · LW(p) · GW(p)
I guess in this case I'm arguing that it's accidentally, accidentally, productive.
↑ comment by CronoDAS · 2024-06-02T02:13:57.206Z · LW(p) · GW(p)
I wrote [a two paragraph explanation](https://www.lesswrong.com/posts/4ceKBbcpGuqqknCj9/the-two-paragraph-argument-for-ai-risk [LW · GW] of AI doom not too long ago.
↑ comment by metachirality · 2024-05-30T06:14:19.068Z · LW(p) · GW(p)
Decision theory/trade reasons
I think this still means MIRI is correct when it comes to the expected value though
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-05-30T17:08:09.142Z · LW(p) · GW(p)
If you're a longtermist, sure.
If you just want to survive, not clearly.
comment by Stephen McAleese (stephen-mcaleese) · 2024-05-30T19:16:37.083Z · LW(p) · GW(p)
Is MIRI still doing technical alignment research as well?
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T20:26:55.510Z · LW(p) · GW(p)
Yes.
comment by trevor (TrevorWiesinger) · 2024-05-30T02:46:20.155Z · LW(p) · GW(p)
One of the main bottlenecks on explaining the full gravity of the AI situation to people is that they're already worn out from hearing about climate change, which for decades has been widely depicted as an existential risk with the full persuasive force of the environmentalism movement.
Fixing this rather awful choke point could plausibly be one of the most impactful things here. The "Global Risk Prioritization" concept is probably helpful for that but I don't know how accessible it is. Heninger's series analyzing the environmentalist movement [? · GW] was fantastic, but the fact that it came out recently instead of ten years ago tells me that the "climate fatigue" problem might be understudied, and evaluation of climate fatigue's difficulty/hopelessness might yield unexpectedly hopeful results.
Replies from: Seth Herd, steve2152↑ comment by Seth Herd · 2024-05-30T03:23:29.829Z · LW(p) · GW(p)
The notion of a new intelligent species being dangerous is actually quite intuitive, and quite different from climate change. Climate change is more like arguing for the risks of more-or-less aligned AGI - complex, debatable, and non-intuitive. One reason I like this strategy is that it does not conflate the two.
The relevant bit of the climate crisis to learn from in that series is: don't create polarization unless the decision-makers mostly sit on one side of the polarizing line. Polarization is the mind-killer.
↑ comment by Steven Byrnes (steve2152) · 2024-05-31T14:49:03.422Z · LW(p) · GW(p)
Note that this kind of messaging can (if you’re not careful) come across as “hey let’s work on AI x-risk instead of climate change”, which would be both very counterproductive and very misleading—see my discussion here [LW · GW].
comment by Thomas Kwa (thomas-kwa) · 2024-05-30T06:39:36.450Z · LW(p) · GW(p)
Does MIRI have a statement on recent OpenAI events? I'm pretty excited about frank reflections on current events as helping people to orient.
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T17:52:07.927Z · LW(p) · GW(p)
Rob Bensinger has tweeted about it some.
Overall we continue to be pretty weak in on the "wave" side, having people comment publicly on current events / take part in discourse, and the people we hired recently are less interested in that and more interested in producing the durable content. We'll need to work on it.
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2024-06-05T15:57:08.026Z · LW(p) · GW(p)
The stuff I've been tweeting doesn't constitute an official MIRI statement — e.g., I don't usually run these tweets by other MIRI folks, and I'm not assuming everyone at MIRI agrees with me or would phrase things the same way. That said, some recent comments and questions from me and Eliezer:
- May 17: Early thoughts on the news about OpenAI's crazy NDAs.
- May 24: Eliezer flags that GPT-4o can now pass one of Eliezer's personal ways of testing whether models are still bad at math.
- May 29: My initial reaction to hearing Helen's comments on the TED AI podcast. Includes some follow-on discussion of the ChatGPT example, etc.
- May 30: A conversation between me and Emmett Shear about the version of events he'd tweeted in November. (Plus a comment from Eliezer.)
- May 30: Eliezer signal-boosting a correction from Paul Graham.
- June 4: Eliezer objects to Aschenbrenner's characterization of his timelines argument as open-and-shut "believing in straight lines on a graph".
↑ comment by Rob Bensinger (RobbBB) · 2024-06-05T16:11:10.288Z · LW(p) · GW(p)
As is typical for Twitter, we also signal-boosted a lot of other people's takes. Some non-MIRI people whose social media takes I've recently liked include Wei Dai, Daniel Kokotajlo, Jeffrey Ladish, Patrick McKenzie, Zvi Mowshowitz, Kelsey Piper, and Liron Shapira.
comment by Alex_Altair · 2024-05-29T20:46:55.004Z · LW(p) · GW(p)
stable, durable, proactive content – called “rock” content
FWIW this is conventionally called evergreen content.
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-29T20:50:38.300Z · LW(p) · GW(p)
Indeed! However, I'd been having stress dreams for months about getting drowned in the churning tidal wave of the constant news cycle, and I needed something that fit thematically with 'wave.' :-)
comment by davekasten · 2024-05-30T21:39:24.640Z · LW(p) · GW(p)
Because it's relevant to my professional interest -- who do you think is really, really world class today on making "rock" and "wave" content ?
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T22:06:33.058Z · LW(p) · GW(p)
Gosh, I haven't really conducted a survey here or thought deeply about it, so this answer will be very off the cuff and not very 2024. Some of the examples that come to mind are the major media empires of, e.g. Brene Brown or Gretchen Rubin.
comment by mako yass (MakoYass) · 2024-06-01T23:14:50.922Z · LW(p) · GW(p)
We are not investing in grass-roots advocacy, protests, demonstrations, and so on.
I like this, I'd be really interested to ask you, given that you're taking a first principles no bullshit approach to outreach, what do you think of protest in general?
Every protest I've witnessed seemed to be designed to annoy and alienate its witnesses, making it as clear as possible that there was no way to talk to these people, that their minds were on rails. I think most people recognize that as cult shit and are alienated by that.
A leftist friend once argued that protest is not really a means, but a reward, a sort of party for those who contributed to local movementbuilding. I liked that view. Perhaps we should frame our public gatherings to be closer to being that. If there is to be chanting of slogans, it must be an organic ebullition of the spirit of a group that was formed around some more productive purpose than that, maybe the purpose of building inclusive networks for shared moral purpose? (EA but broader?)
Replies from: RobbBB↑ comment by Rob Bensinger (RobbBB) · 2024-06-03T00:54:50.163Z · LW(p) · GW(p)
Every protest I've witnessed seemed to be designed to annoy and alienate its witnesses, making it as clear as possible that there was no way to talk to these people, that their minds were on rails. I think most people recognize that as cult shit and are alienated by that.
In the last year, I've seen a Twitter video of an AI risk protest (I think possibly in continental Europe?) that struck me as extremely good: calm, thoughtful, accessible, punchy, and sensible-sounding statements and interview answers. If I find the link again, I'll add it here as a model of what I think a robustly good protest can look like!
A leftist friend once argued that protest is not really a means, but a reward, a sort of party for those who contributed to local movementbuilding. I liked that view.
I wouldn't recommend making protests purely this. A lot of these protests are getting news coverage and have a real chance of either intriguing/persuading or alienating potential allies; I think it's worth putting thought into how to hit the "intriguing/persuading" target, regardless of whether this is "normal" for protests.
But I like the idea of "protest as reward" as an element of protests, or as a focus for some protests. :)
comment by TerriLeaf · 2024-05-30T17:40:44.905Z · LW(p) · GW(p)
I am not an expert, however I'd like to make a suggestion regarding the strategy. The issue I see with this approach is that policymakers have a very bad track record of listening to actual technical people (see environmental regulations).
Generally speaking they will only listen when this is convenient to them (some immediate material benefit is on the table), or if there is very large popular support, in which case they will take action in the way that allows them to put the least effort they can get away with.
There is, however, one case where technical people can get their way (at times): Military analysts
Strategic analysts to be more precise; apparently the very real threat of nuclear war is enough to actually get some things done. Nuclear weapons share some qualities with AI systems envisioned by MIRI:
- They can "end the world"
- They have been successfully contained (only a small number of actors have access to them)
- World-wide, Industry-wide control on their development
- At one point, there were serious discussion of halting development altogether
- "Control" has persisted over long time periods
- No rogue user (as of now)
I think military analysts could be a good target to try to reach out to, they are more likely to listen and understand technical arguments than policymakers for sure, and they already have experience in navigating the political world. In an ideal scenario AI could be treated like another class of WMDs like nuclear, chemical and bioweapons.
Replies from: nathan-helm-burger, gretta-duleba↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-06-08T15:29:44.993Z · LW(p) · GW(p)
I absolutely agree that I see promise in reaching out to military analysts and explaining the national security implications to them. I very much disagree that AI is successfully contained. The open-weights models being released currently seem to be only a couple years behind the industry-controlled models. Thus, even if we regulate industry to get them to make their AIs behave safely, we haven't tackled the open-weights problem at all.
Halting the industrial development of AI would certainly slow it down, but also very likely not halt development entirely.
So yes, the large scale industrial development of AI is producing the most powerful results and is the most visible threat, but is not the only threat. Millions of rogue users are currently training open weights AIs on datasets of 'crime stories' demonstrating AI assistants aiding their users in committing crimes. This is part of the 'decensoring process'. Most of these users are just doing this for harmless fun, to make the the AI into an interesting conversation partner. But it does have the side-effect of making the model willing to help out with even dangerous projects, like helping terrorists develop weapons and plan attacks.
↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-31T01:52:10.053Z · LW(p) · GW(p)
Seems right, thanks.
comment by Anthony Bailey (anthony-bailey) · 2024-06-01T22:06:45.512Z · LW(p) · GW(p)
What We’re Not Doing ... We are not investing in grass-roots advocacy, protests, demonstrations, and so on. We don’t think it plays to our strengths, and we are encouraged that others are making progress in this area.
Not speaking for the movement, but as a regular on Pause AI this makes sense to me. Perhaps we can interact more, though, and in particular I'd imagine we might collaborate on testing the effectiveness of content in changing minds.
Execution ... The main thing holding us back from realizing this vision is staffing. ... We hope to hire more writers ... and someone to specialize in social media and multimedia. Hiring for these roles is hard because [for the] first few key hires we felt it was important to check all the boxes.
I get the need for a high bar, but my guess is MIRI could try to grow ten times faster than the post indicates. More dakka: more and better content. If the community could provide necessary funding and quality candidate streams, would you be open to dialing the effort up like that?
comment by bhauth · 2024-06-01T16:00:05.006Z · LW(p) · GW(p)
I understand why MIRI has Yudkowsky, Bourgon, and Soares as "spokespeople" but I don't think they're good choices for all types of communications. You should look at popular science communicators such as Neil deGrasse Tyson or Malcolm Gladwell or popular TED talk presenters to see what kind of spokespeople appeal to regular people. I think it would be good to have someone more like that, but, you know...smarter and not wrong as often.
When I look at popular media, the person whose concerns about AI risks are cited most often is probably Geoffrey Hinton.
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-06-02T02:17:04.073Z · LW(p) · GW(p)
As I mentioned in the post we are looking to hire or partner with a new spokesperson if we can find someone suitable. We don't think it will be easy to find someone great; it's a pretty hard job.
comment by Sen · 2024-06-01T13:41:41.134Z · LW(p) · GW(p)
I am not convinced MIRI has given enough evidence to support the idea that unregulated AI will kill everyone and their children. Most of their projects are either secret or old papers. The only papers which have been produced after 2019 are random irrelevant math papers. Most of the rest of their papers are not even technical in nature and contain a lot of unverified claims. They have not even produced one paper since the breakthrough in LLM technology in 2022. Even among the papers which do indicate risk, there is no consensus among scientific peers that this is true or necessarily an extinction risk. Note: I am not asking for "peer review" as a specific process, just some actual consensus among established researchers to sift mathematical facts from conjecture.
Policymakers should not take seriously the idea of shutting down normal economic activity until this is formally addressed.
Replies from: habryka4, Lukas_Gloor↑ comment by habryka (habryka4) · 2024-06-01T16:20:51.453Z · LW(p) · GW(p)
just some actual consensus among established researchers to sift mathematical facts from conjecture.
"Scientific consensus" is a much much higher bar than peer review. Almost no topic of relevance has a scientific consensus (for example, there exists basically no trustworthy scientific for urban planning decisions, or the effects of minimum wage law, or pandemic prevention strategies, or cyber security risks, or intelligence enhancement). Many scientific peers think there is an extinction risk.
I think demanding scientific consensus is an unreasonably high bar that would approximately never be met in almost any policy discussion.
Replies from: Sen↑ comment by Sen · 2024-06-13T16:49:56.266Z · LW(p) · GW(p)
Obviously I meant some kind of approximation of consensus or acceptability derived from much greater substantiation. There is no equivalent to Climate Change or ZFC in the field of AI in terms of acceptability and standardisation. Matthew Barnett made my point better in the above comments.
Yes, most policy has no degree of consensus. Most policy is also not asking to shut down the entire world's major industries. So there must be a high bar. A lot of policy incidentally ends up being malformed and hurting people, so it sounds like you're just making the case for more "consensus" and not less.
↑ comment by Lukas_Gloor · 2024-06-01T14:20:00.790Z · LW(p) · GW(p)
I am not convinced MIRI has given enough evidence to support the idea that unregulated AI will kill everyone and their children.
The way you're expressing this feels like an unnecessarily strong bar.
I think advocacy for an AI pause already seems pretty sensible to me if we accept the following premises:
- The current AI research paradigm mostly makes progress in capabilities before progress in understanding.
(This puts AI progress in a different reference class from most other technological progress, so any arguments with base rates from "technological progress normally doesn't kill everyone" seem misguided.) - AI could very well kill most of humanity, in the sense that it seems defensible to put this at anywhere from 20-80% (we can disagree on the specifics of that range, but that's where I'd put it looking at the landscape of experts who seem to be informed and doing careful reasoning (so not LeCun)).
- If we can't find a way to ensure that TAI is developed by researchers and leaders who act with a degree of responsibility proportional to the risks/stakes, it seems better to pause.
Edited to add the following:
There's also a sense in which whether to pause is quite independent from the default risk level. Even if the default risk were only 5%, if there were a solid and robust argument that pausing for five years will reduce it to 4%, that's clearly very good! (It would be unfortunate for the people who will die preventable deaths in the next five years, but it still helps overall more people to pause under these assumptions.)
↑ comment by Sen · 2024-06-05T03:21:59.812Z · LW(p) · GW(p)
The bar is very low for me: If MIRI wants to demand the entire world shut down an entire industry, they must be an active research institution actively producing agreeable papers.
AI is not particularly unique even relative to most technologies. Our work on chemistry in the 1600's-1900's far outpaced our level of true understanding of chemistry, to the point where we only had a good model of an atom in the 20th century. And I don't think anyone will deny the potential dangers of chemistry. Other technologies followed a similar trajectory.
We don't have to agree that the range is 20-80% at all, never mind the specifics of it. Most polls demonstrate researchers find around 5-10% chance of total extinction on the high end. MIRI's own survey finds a similar result! 80% would be insanely extreme. Your landscape of experts is, I'm guessing, your own personal follower list and not statistically viable.
comment by Petr 'Margot' Andreev (petr-andreev) · 2024-06-02T01:52:07.560Z · LW(p) · GW(p)
- Problems of Legal Regulation
1.1. The adoption of such laws is long way
Usually, it is a centuries-long path: Court decisions -> Actual enforcement of decisions -> Substantive law -> Procedures -> Codes -> Declaration then Conventions -> Codes.
Humanity does not have this much time, it is worth focusing on real results that people can actually see. It might be necessary to build some simulations to understand which behavior is irresponsible.
Where is the line between creating a concept of what is socially dangerous and what are the ways to escape responsibility?
As a legal analogy, I would like to draw attention to the criminal case of Tornado Cash.
https://uitspraken.rechtspraak.nl/details?id=ECLI:NL:RBOBR:2024:2069
The developer created and continued to improve an unstoppable program that possibly changed the structure of public transactions forever. Look where the line is drawn there. Can a similar system be devised concerning the projection of existential risks?
1.2. The difference between substantive law and actual law on the ground, especially in countries built on mysticism and manipulation. Each median group of voters creates its irrational picture of the world within each country. You do not need to worry about floating goals.
There are enough people in the world in a different information bubbles than you, so you can be sure that there are actors with values opposite to yours.
1.3. Their research can be serious, but the worldview simplified and absurd. At the same time, resources can be extensive enough for technical workers to perform their duties properly.
- The Impossibility of Ideological Influence
2.1. There is no possibility of ideologically influencing all people simultaneously and all systems.
2.2. If I understand you correctly, more than 10 countries can spend huge sums on creating AI to accelerate solving scientific problems. Many of these countries are constantly struggling for their integrity, security, solving national issues, re-election of leaders, gaining benefits, fulfilling the sacred desires of populations, class, other speculative or even conspiratorial theories. Usually, even layers of dozens of theories.
2.3. Humanity stands on the brink of new searches for the philosopher's stone, and for this, they are ready to spend enormous resources. For example, the quantum decryption of old Satoshi wallets plus genome decryption can create the illusion of the possibility of using GAI to solve the main directions of any transhumanist’s alhimists desires, to give the opportunity to defeat death within the lifetime of this or the next two generations. Why should a conditional billionaire and/or state leader refuse this?
Or, as proposed here, the creation of a new super IQ population, again, do not forget that some of the beliefs can be antagonistic.
Even now, from the perspective of AI, predicting the weather in 2100 is somehow easier than in 2040. Currently, there are about 3-4 countries that can create Wasteland-type weather, they partially come into confrontation approximately every five years. Each time, this is a tick towards a Wasteland with a probability of 1-5%. If this continues, the probability of Wasteland-type weather by 2040 will be:
1−0.993=0.0297011 - 0.99^3 = 0.0297011−0.993=0.029701
1−0.953=0.1426251 - 0.95^3 = 0.1426251−0.953=0.142625
By 2100, if nothing changes:
1−0.9915=0.13991 - 0.99^{15} = 0.13991−0.9915=0.1399
1−0.9515=0.46321 - 0.95^{15} = 0.46321−0.9515=0.4632
(A year ago, my predictions were more pessimistic as I was in an information field that presented arguments for the Wasteland scenario in the style of "we'll go to heaven, and the rest will just die." Now I off that media =) to be less realistic, Now it seems that this will be more related to presidential cycles and policy, meaning they will occur not every year, but once every 5 years, as I mentioned earlier, quite an optimistic forecast)
Nevertheless, we have many apocalyptic scenarios: nuclear, pandemic, ecological (the latter is exacerbated by the AI problem, as it will be much easier to gather structures and goals that are antagonistic in aims).
3. Crisis of rule of law
In world politics, there has been a rollback of legal institutions since 2016 (see UN analytics). These show crisis of common values. Even without the AI problem, this usually indicates either the construction of a new equilibrium or falling into chaos. I am a pessimist here and believe that in the absence of normalized common values, information bubbles due to the nature of hysteria become antagonistic (simply put, wilder information flows win, more emotional and irrational). But vice verse this is a moment where MIRI could inject value that existential safety is very important. Especially now cause any injection in out doom clock bottom could create effect that MIRI solved it
4. Problems of Detecting AI Threats
4.1. AI problems are less noticeable than nuclear threats (how to detect these clusters, are there any effective methods?).
4.2. Threat detection is more blurred, identifying dangerous clusters is difficult. The possibility of decentralized systems, like blockchain, and their impact on security. (decentralized computing is rapidly developing, there is progress in superconductors, is this a problem from the perspective of AI security detection?).
Questions about the "Switch off" Technology
5.1. What should a program with a "switch" look like? What is its optimal structure:
a) Proprietary software, (which blocks, functions are recommended to be closed from any distribution)
b) Close/Open API, (what functions can MIRI or other laboratories provide, but with the ability to turn off at any moment, for example, enterprises like OpenAI)
c) Open source with constant updates, (open libraries, but which require daily updates to create the possibility of remotely disabling research code)
d) Open code, (there is an assumption that with open code there is less chance that AI will come into conflict with other AIs, AI users with other AI users, open code can provide additional chances that the established equilibrium between different actors will be found, and they will not mutually annihilate each other. Because they could better in prediction each other behavior)
5.2. The possibility of using multi-signatures and other methods.
How should the button work? Should such a button and its device be open information? Of another code structure? another language? Analogues tech
Are there advantages or disadvantages of shutdown buttons, are there recommendations like at least one out of N pressed, which system seems the most sustainable?
5.3. Which method is the most effective?
Benefits and Approval
6.1. What benefits will actors gain by following recommendations? Leaders of most countries make decisions not only and not so much from their own perspective, but from the irrational desires of their sources of power, built on dozens of other, usually non-contradictory but different values.
6.2. Possible forms of approval and assistance in generating values. Help to defend ecology activists to defend from energy crisis? (from my point of view AI development not take our atoms, but will take our energy, water, sun, etc)
6.3. Examples of large ‘switch off’ projects, for AI infrastructure with enough GPU, electricity, like analogies nuclear power plants but for AI. If you imagine such objects plants what rods for reactions should be, how to pull them out, what "explosives" over which pits should be laid to dump all this into acid or another method of safe destroying
7.1. Questions of approval and material assistance for such enterprises. What are the advantages of developing such institutions under MIRI control compared to
7.2. The hidden maintenance of gray areas on the international market. Why is the maintenance of the gray segment less profitable than cooperation with MIRI from the point of view of personal goals, freedom, local goals, and the like?
Trust and Bluff
8.1. How can you be sure of the honesty of the statements? MIRI that it is not a double game. And that these are not just declarative goals without any real actions? From my experience, I can say that neither in poker bot cases nor in the theft of money using AI in the blockchain field did I feel any feedback from the Future Life Institute project. To go far, I did not even receive a single like from reposts on Twitter. There were no automatic responses to emails, etc. And in this, I agree with Matthew Barnett that there is a problem with effectiveness.
What to present to the public? What help can be provided? Help in UI analytics? Help in investigating specific cases of violations using AI?
For example, I have a problem where I need for consumer protection to raise half a million pounds against AI that stole money through low liquidity trading on Binance, how can I do this?
I tried writing letters to the institute and to 80,000 hours, zero responses
SEC, Binance, and a bunch of regulators. They write no licenses, okay no. But why does and 80,000 generally not respond? I do not understand.
8.2. Research in open-source technologies shows greater convergence of trust. Open-source programs can show greater convergence in cooperation due to the simpler idea of collaboration and solving the prisoner's dilemma problem not only through past statistics of another being but also through its open-to-collaboration structure. In any case, GAI will eventually appear, possibly open monitoring of each other's systems will allow AI users not to annihilate each other.
8.3. Comparison with the game theory of the Soviet-Harvard school and the need for steps towards security. The current game theory is largely built on duel-like representations of game theory, where damage to the opponent is an automatic victory, and many systems at the local level continue to think they are there.
Therefore, it is difficult for them to believe in the mutual benefit of systems, that it is about WIN-WIN, cooperation, and not empty talk or just a scam for redistribution of influence and media manipulation.
AI Dangers
9.1. What poses a greater danger: multiple AIs, two powerful AIs, or one actor with a powerful AI?
9.2. Open-source developments in the blockchain field can be both safe and dangerous? Are there any reviews?
this is nice etherium foundation list of articles:
what do you think about:
Open Problems in Cooperative AI, Cooperative AI: machines must learn to find common ground, etc articles?
9.3. Have you considered including the AI problem in the list of Universal jurisdiction https://en.wikipedia.org/wiki/Universal_jurisdiction
Currently, there are no AI problems or, in general, existential crimes against humanity. Perhaps it is worth joining forces with opponents of eugenics, eco-activists, nuclear alarmists, and jointly prescribing and adding crimes against existential risks (to prevent the irresponsible launch of projects that with probabilities of 0.01%+ can cause severe catastrophes, humanity avoided the Oppenheimer risk with the hydrogen bomb, but not with Chernobyl, and we do not want giga-projects to continue allowing probabilities of human extinction, but treated it with neglect for local goals).
In any case, introducing the universal jurisdiction nature of such crimes can help in finding the “off” button for the project if it is already launched by attracting the creators of a particular dangerous object. This category allow states or international organizations to claim criminal jurisdiction over an accused person regardless of where the alleged crime was committed, and regardless of the accused's nationality, country of residence, or any other relation to the prosecuting entity
9.4. And further the idea with licensing, to force actors to go through the verification system on the one hand, and on the other, to ensure that any technology is refined and becomes publicly available.
https://uitspraken.rechtspraak.nl/details?id=ECLI:NL:RBOVE:2024:2078
https://uitspraken.rechtspraak.nl/details?id=ECLI:NL:RBOVE:2024:2079
A license is very important to defend a business, its CEO, and colleagues from responsibility. Near-worldwide monopolist operators should work more closely to defend the rights of their average consumer to prevent increased regulation. Industries should establish direct contracts with professional actors in their fields in a B2B manner to avoid compliance risks with consumers.
Such organisation as MIRI could be strong experts that could check AI companies for safety especially they large enough to create existential risk or by opposite penalties and back of all sums that people accidentally lost from too weak to common AI attacks frameworks. People need to see simple show of their defence against AI and help from MIRI, 80000 and other effective altruist especially against AI bad users that already misalignment and got 100kk+ of dollars. It is enough to create decentralized if not now than in next 10 years
Examples and Suggestions
10.1. Analogy with the criminal case of Tornado Cash. In the Netherlands, there was a trial against a software developer who created a system that allows decentralized perfect unstoppable crime. It specifically records the responsibility of this person due to his violation of financial world laws. Please note if it can be somehow adapted for AI safety risks, where lines and red flags.
10.2. Proposals for games/novels. What are the current simple learning paths, in my time it was HPMOR -> lesswrong.ru -> lesswrong.com.
At present, Harry Potter is already outdated for the new generation, what are the modern games/stories about AI safety, how to further direct? How about an analogue of Khan Academy for schoolchildren? MIT courses on this topic?
Thank you for your attention. I would appreciate it if you could point out any mistakes I have made and provide answers to any questions. While I am not sure if I can offer a prize for the best answer, I am willing to donate $100 to an effective fund of your choice for the best engagement response.
I respect and admire all of you for the great work you do for the sustainability of humanity!
Replies from: nathan-helm-burger↑ comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-06-08T15:22:17.064Z · LW(p) · GW(p)
I think my model of AI causing increasing amounts of trouble in the world, eventually even existential risk for humanity, doesn't look like a problem which is well addressed by an 'off switch'. To me, the idea of an 'off switch' suggests that there will be a particular group (e.g. an AI company) which is running a particular set of models on a particular datacenter. Some alarm is triggered and either the company or their government decides to shut down the company's datacenter.
I anticipate that, despite the large companies being ahead in AI technology, they will also be ahead in AI control, and thus the problems they first exhibit will likely be subtle ones like gradual manipulation of users. At what point would such behavior, if detected, lead to a sufficiently alarmed government response that they would trigger the 'off switch' for that company? I worry that even if such subversive manipulation were detected, the slow nature of such threats would give the company time to issue and apology and say that they were deploying a fixed version of their model. This seems much more like a difficult to regulate grey area than would be, for instance, the model being caught illicitly independently controlling robots to construct weapons of war. So I do have concerns that in the longer term, if the large companies continue to be unsafe, they will eventually build AI so smart and capable and determined to escape that it will succeed. I just expect that to not be the first dangerous effect we observe.
In contrast, I expect that the less powerful open weights models will be more likely to be the initial cause of catastrophic harms which lead clearly to significant crimes (e.g. financial crimes) or many deaths (e.g. aiding terrorists in acquiring weapons). The models aren't behind an API which can filter for harmful use, and the users can remove any 'safety inclinations' which have been trained into the model. The users can fine-tune the model to be an expert in their illegal use-case. For such open weights models, there is no way for the governments of the world to monitor them or have an off-switch. They can be run on the computers of individuals. Having monitors and off-switches for every sufficiently powerful individual computer in the world seems implausible.
Thus, I think the off-switch only addresses a subset of potential harms. I don't think it's a bad idea to have, but I also don't think it should be the main focus of discussion around preventing AI harms.
My expectation is that the greatest dangers we are likely to first encounter (and thus likely to constitute our 'warning shots' if we get any) are probably going to be one of two types:
- A criminal or terrorist actor using a customized open-weights model to allow them to undertake a much more ambitious crime or attack than they could have achieved without the model.
- Eager hobbyists pushing models into being self-modifying agents with the goal of launching a recursive self-improvement cycle, or the goal of launching a fully independent AI agent into the internet for some dumb reason. People do dumb things sometimes. People are already trying to do both these things. The only thing stopping this from being harmful at present is that the open source models are not yet powerful enough to effectively become independent rogue agents or to self-improve.
- Certainly the big AI labs will get to the point of being able to do these things first, but I think they will be very careful not to let their expensive models escape onto the internet as rogue agents.
- I do expect the large labs to try to internally work on recursive self-improvement, but I have some hope that they will do so cautiously enough that a sudden larger-than-expected success won't take them unawares and escape before they can stop it.
- So the fact that the open source hobbyist community is actively trying to do these dangerous activities, and no one is even discussion regulations to shut this sort of activity down, means that we have a time bomb with an unknown fuse ticking away. How long will it be until the open source technology improves to the point that these independently run AIs cross their 'criticality point' and successfully start to make themselves increasingly wealthy / smart / powerful / dangerous?
Another complicating factor is that trying to plan for 'defense from AI' is a lot like trying to plan for 'defense from humans'. Sufficiently advanced general AIs are intelligent agents like humans are. I would indeed expect an AI which has gain independence and wealth to hire and/or persuade humans to work for it (perhaps without even realizing that they are working for an AI rather than a remote human boss). Such an AI might very well set up shell companies with humans playing the role of CEOs but secretly following orders from the AI. Similarly, an AI which gets very good at persuasion might be able to manipulate, radicalize, and fund terrorist groups into taking specific violent actions which secretly happen to be arranged to contribute to the AI's schemes (without the terrorist groups even realizing that their funding and direction is coming from an AI).
These problems, and others like them, have been forecasted by AI safety groups like MIRI. I don't, however, think that MIRI is well-placed to directly solve these problems. I think many of the needed measures are more social / legal rather than technical. MIRI seems to agree, which is why they've pivoted towards mainly trying to communicate about the dangers they see to the public and to governments. I think our best hope to tackle these problems comes from action being taken by government organizations, who are pressured by concerns expressed by the public.
comment by Gunnar_Zarncke · 2024-05-30T17:11:22.190Z · LW(p) · GW(p)
I have never heard of the rock/wave communication strategy and can't seem to google it.
these are pretty standard communications tactics in the modern era.
Is this just unusual naming? Anybody have links?
Replies from: gretta-duleba↑ comment by Gretta Duleba (gretta-duleba) · 2024-05-30T17:29:30.298Z · LW(p) · GW(p)
Oh, yeah, to be clear I completely made up the "rock / wave" metaphor. But the general model itself is pretty common I think; I'm not claiming to be inventing totally new ways of spreading a message, quite the opposite.
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-05-30T22:45:12.719Z · LW(p) · GW(p)
I like it. It's quite evocative.
comment by Ebenezer Dukakis (valley9) · 2024-06-05T03:00:34.930Z · LW(p) · GW(p)
With regard to the "Message and Tone" section, I mostly agree with the specific claims. But I think there is danger in taking it too far. I strongly recommend this post: https://www.lesswrong.com/posts/D2GrrrrfipHWPJSHh/book-review-how-minds-change [LW · GW]
I'm concerned that the AI safety debate is becoming more and more polarized, sort of like US politics in general. I think many Americans are being very authentic and undiplomatic with each other when they argue online, in a way that doesn't effectively advance their policy objectives. Given how easily other issues fall into this trap, it seems reasonable on priors to expect the same for AI. Then we'll have a "memetic trench warfare" situation where you have a lot of AI-acceleration partisans who are entrenched in their position. If they can convince just one country's government to avoid cooperating with "shut it all down", your advocacy could end up doing more harm than good. So, if I were you I'd be a bit more focused on increasing the minimum level of AI fear in the population, as opposed to optimizing for the mean or median level of AI fear.
With regard to polarization, I'm much more worried about Eliezer, and perhaps Nate, than I am about Rob. If I were you, I'd make Rob spokesperson #1, and try to hire more people like him.
comment by Review Bot · 2024-05-29T21:46:06.078Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2025. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?